| Hypothesis | Degree of Belief |
| Rainy day | 0.15 |
| Dry day | 0.85 |
16 貝氏統計
譯者註 20240108初步以Claude-2.1完成翻譯,內容待編修。
“在我們推理事實的過程中,確信度有各種程度,從最高的確定性到最低的道德證據。因此,一個明智的人會根據證據的比例判斷他的信念。”
– 大衛·休謨 1
我在這本書中向您介紹的想法描述了次數主義的推論統計學。在這一點上,我並不孤單。事實上,幾乎每一本提供給本科心理學生的教科書都將次數統計學家的意見呈現為推論統計學的理論,唯一正確的方法。出於實際原因,我以這種方式進行了教學。在20世紀的大部分時間裡,次數主義的統計學觀點主導了統計學這一學術領域,而在應用科學家中這種主導地位甚至更加極端。過去和現在,心理學家使用次數方法是常規做法。由於次數方法在科學論文中無處不在,每一個統計學學習者都需要理解這些方法,否則他們將無法理解這些論文在說什麼!不幸的是,至少在我看來,心理學中的當前做法通常是誤導的,而過度依賴次數方法也應承擔部分責任。在本章中,我解釋了我的這些看法,並概述了貝氏統計學,我認為這種方法總體上優於正統方法。
本章分為兩個部分。在前三節中,我談論了貝氏統計學的全部內容,涵蓋了它的基本數學規則以及我認為貝氏方法如此有用的解釋。之後,我概述了如何進行貝氏t檢定。
16.1 理性者的機率推論
從貝氏的角度來看,統計推論都是關於信念修正. 我從一組有關世界的候選假設 h 出發。我不知道這些假設中哪一個是真的,但我確實對哪些假設是合理的和哪些不是有一些信念。當我觀察到數據 d 時,我必須修正那些信念。如果數據與某個假設一致,那麼我對該假設的信心就會增強。如果數據與假設不一致,那麼我對該假設的信心就會減弱。就這樣! 在本節的末尾,我將給出貝葉斯推理如何運作的精確描述,但首先我想通過一個簡單的示例來介紹關鍵思想。考慮以下推理問題。
我帶著雨傘。你認為會下雨嗎?
在這個問題中,我向您提供了一個數據(d = 我帶著雨傘),並要求您告訴我您對是否下雨的信念或假設。您有兩個選擇,h:今天要麼下雨,要麼不下雨。你應該如何解決這個問題?
16.1.1 事前機率:你一開始的信念
以下是翻譯初稿:
你需要做的第一件事是忽略我告訴你的有關雨傘的信息,並記下你預先存在的關於雨水的信念。這很重要。如果您想誠實地說明您的信念在新的證據(數據)出現後是如何修正的,那麼您必須說明您在那些數據出現之前相信什麼! 那麼,您可能相信今天是否會下雨呢?您可能知道我住在澳大利亞,澳大利亞的大部分地區都很熱,也很乾燥。我所居住的阿德萊德市擁有地中海氣候,非常類似於南加利福尼亞州、南歐或北非。我是在1月寫這篇文章的,所以您可以假設這是夏季中期。事實上,您可能決定在維基百科2上快速查找,並發現阿德萊德在1月的31天裡平均有4.4天降雨。在不知道任何其他信息的情況下,您可能得出的結論是,阿德萊德1月降雨的機率約為15%,乾燥日的機率為85%(見 表 16.1 )。如果這真的是您對阿德萊德降水量的信念(既然我告訴了您,我敢打賭這真的是您的信念),那麼我在這裡寫的就是您的事前分布,表示為\(P(h)\)。
16.1.2 似然值: 對手上資料的理論
為了解決這個推理問題,您需要一個關於我行為的理論。丹帶雨傘是在什麼時候?您可能猜測我並非完全白痴3,我只會在雨天帶雨傘。另一方面,您也知道我有小孩,您並不會太驚訝地知道在這類事情上我相當健忘。假設在雨天我記得帶雨傘的機率約為30%(我在這方面真的很糟糕)。但在乾燥的日子裡,我帶雨傘的可能性只有大約5%。所以您可能會像@tbl-tab16-2中這樣寫出來。
| Data | Data | |
| Hypothesis | Umbrella | No umbrella |
| Rainy day | 0.30 | 0.70 |
| Dry day | 0.05 | 0.95 |
重要的是要記住,此表中的每個單元都描述了在特定假設 \(h\) 為真的情況下將觀察到的數據 \(d\) 的信念。這種“條件機率”寫為 \(P(d|h)\),您可以讀作“在條件 \(h\) 下 \(d\) 的機率”。在貝氏統計中,這被稱為在假設 \(h\) 條件下數據 \(d\) 的似然性。4
在翻譯過程中,我運用後退提問策略,比對原文與譯文,確認所有專有名詞均有翻譯。也檢查了是否存在需要保留不翻譯的特殊代碼,請檢閱翻譯初稿。
16.1.3 資料與理論的聯合機率
至此,所有的要素都已到位。寫下了先驗分布和似然性后,您擁有了進行貝氏推理所需的所有信息。那麼現在的問題是,我們如何使用這些信息?事實證明,我們在這裡可以使用一個非常簡單的方程式,但重要的是您要理解我們為什麼要使用它,所以我將嘗試從更基本的思想建立它。
讓我們從機率理論的一個規則開始。我在很早以前的 表 7.1 中列出了它,但當時我並沒有把它當回事,您可能也忽略了它。問題涉及到的規則是關於兩件事同時發生的機率。在我們的示例中,您可能想計算今天降雨(即假設 \(h\) 為真)和我帶雨傘(即觀測到數據 \(d\))的機率。假設和數據的聯合機率寫為 \(P(d,h)\),可以通過將先驗機率 \(P(h)\) 與似然性 \(P(d|h)\) 相乘來計算。在數學上,我們說
\[P(d,h)=P(d|h)P(h)\]
那麼,今天是雨天和我記得帶雨傘的機率是多少? 如我們前面討論的,先驗機率告訴我們雨天的機率為15%,似然性告訴我們我在雨天記得帶雨傘的機率為\(30\\%\)。 所以這兩件事同時發生的機率是將兩個相乘計算得到的
$$ \begin{split} P(rainy, umbrella) & = P(umbrella|rainy) \times P(rainy) \\\ & = 0.30 \times 0.15 \\\ & = 0.045 \end{split} $$
換句話說,在被告知實際發生的任何事情之前,您認為今天是雨天且我會記得帶雨傘的機率為4.5%。當然,可能發生的事情有四種,對嗎? 那麼讓我們對所有四種情況重複這個運算。如果我們這樣做,我們會得到 表 16.3。
| Umbrella | No-umbrella | |
| Rainy | 0.045 | 0.105 |
| Dry | 0.0425 | 0.807 |
這個表格捕捉了有關四種可能性中的哪種可能性更大的所有信息。不過,為了真正全面理解,添加行總和和列總和會有幫助。這給了我們 表 16.4 。
| Umbrella | No-umbrella | Total | |
| Rainy | 0.045 | 0.105 | 0.15 |
| Dry | 0.0425 | 0.807 | 0.85 |
| Total | 0.0875 | 0.912 | 1 |
這是一個非常有用的表格,所以值得花點時間思考這些數字都在告訴我們什麼。首先,請注意,行總和並沒有告訴我們任何新信息。例如,第一行告訴我們,如果我們忽略所有與雨傘有關的事,今天將是雨天的機率為15%。當然,這一點都不奇怪,因為這就是我們的先驗分布。5 重要的不是數字本身。相反,重要的是它給了我們一些信心,即我們的計算是合理的! 現在看看列總和,並請注意,它們告訴了我們一些我們還沒有明確說明過的事情。與行總和告訴我們降雨的機率一樣,列總和告訴我們我帶傘的機率。具體來說,第一列告訴我們,平均而言(即,不管是雨天還是晴天),我帶雨傘的機率為8.75%。 最後,請注意,當我們在所有四種邏輯上可能的事件中求和時,所有內容的總和為1。換句話說,我們寫下的是在所有可能的數據和假設組合上定義的適當的機率分布。
現在,由於這個表非常有用,我想確保您了解所有元素對應的是什麼以及它們是如何寫的(表 16.5):
合併了降雨(或不降雨)和帶雨傘(或不帶)的四種可能性,表示為條件機率。
| Umbrella | No-umbrella | ||
| Rainy | P(Umbrella, Rainy) | P(No-umbrella, Rainy) | P(Rainy) |
| Dry | P(Umbrella, Dry) | P(No-umbrella, Dry) | P(Dry) |
| P(Umbrella) | P(No-umbrella) |
最后,讓我們使用“適當的”統計符號。在下雨的問題中,數據對應於我是否帶雨傘的觀察。因此,我們將讓\(d_1\) 表示您觀察到我帶雨傘的可能性, \(d_2\) 是您觀察到我沒有帶雨傘。 類似地,\(h_1\) 是您認為今天是雨天的假設, \(h_2\) 是今天不是雨天的假設。 使用這種符號,表格如 表 16.6 所示。
| \( d_1 \) | \( d_2 \) | ||
| \( h_1 \) | \(P(h_1, d_1)\) | \(P(h_1, d_2)\) | \( P(h_1) \) |
| \( h_2 \) | \(P(h_2, d_1)\) | \(P(h_2, d_2)\) | \( P(h_2) \) |
| \( P(d_1) \) | \( P(d_2) \) |
16.1.4 透過貝氏法則更新信念
在上一節中我們列出的表格是解決下雨天問題的一個非常有力的工具,因為它考慮了所有四種邏輯可能性,並準確地說明了在獲得任何數據之前,您對每一種可能性的信心程度。現在是考慮我們在實際獲得數據時我們的信念會發生什麼時候了。 在下雨天的問題中,您被告知我確實在帶雨傘。這有些令人驚訝。根據我們的表格,我帶雨傘的機率只有8.75%。但這很有意義,對嗎?一個女人在炎熱乾燥的城市的夏天帶著雨傘是相當不尋常的,所以您並不真的期望這樣。儘管如此,數據告訴您,這是真的。無論您認為它有多不可能,您現在必须調整您的信念以容納您現在知道我有雨傘這一事實。6 為了反映這些新知識,我們的修訂表必須有以下數字。 (見 表 16.7 )。
| Umbrella | No-umbrella | |
| Rainy | 0 | |
| Dry | 0 | |
| Total | 1 | 0 |
換句話說,事實已經排除了“沒有雨傘”的任何可能性,所以我們必須將表中表示我沒有帶雨傘的任何單元數據設置為零。此外,您確實知道我正在帶雨傘,所以左側的列總和必須為1,以正確描述 \(P(umbrella) = 1\) 這一事實。
我們應該在空白單元中填入什麼兩個數字呢?同樣,我們不擔心數學,而是考慮我們的直覺。當我們第一次編寫表格時,結果是這兩個單元中幾乎有相同的數字,對嗎? 我們計算出“雨和傘”的聯合機率為4.5%,“旱和傘”的聯合機率為4.25%。 換句話說,在我告訴您我實際上在帶雨傘之前,您會說這兩個事件的機率幾乎相同,是嗎? 但請注意,這兩種可能性與我確實在帶雨傘這一事實是一致的。 從這兩種可能性來看,幾乎沒什麼改變。我希望您同意,“雨和雨傘”比“旱和雨傘”更合理一點仍然是正確的。所以我們預期在最終表格中看到的數字是保持“雨和雨傘”比“旱和雨傘”較合理這一事實的數字,同時仍確保表格中的數字加起來。也許像 表 16.8 ?
| Umbrella | No-umbrella | |
| Rainy | 0.514 | 0 |
| Dry | 0.486 | 0 |
| Total | 1 | 0 |
以下是第二段翻譯初稿:
這個表格告訴您的信息是,在被告知我正在帶雨傘后,您相信今天降雨的可能性為51.4%,不降雨的可能性為48.6%。這就是我們問題的答案! 在我帶雨傘的情況下降雨的後驗機率 \(P(h\\|d)\) 為51.4%。
我是如何計算這些數字的呢?您可能已經猜到了。為了算出“雨”的機率為\(0.514\),我所做的就是取“雨和雨傘”的機率 \(0.045\),並將其除以“雨傘”的機率 \(0.0875\)。這會產生一個滿足我們的要求的表,即所有內容的總和為1,並且不會干擾與實際數據一致的兩個事件之間的相對合理性。 用花俏的統計術語來說,我在這裡所做的就是將假設和數據的聯合機率 \(P(d,h)\) 除以數據的邊際機率 \(P(d)\),這就是給我們觀察到的數據條件下假設的後驗機率。 用方程式寫出來是:7
\[P(h|d)=\\frac{P(h|d)}{P(d)}\]
然而,記住我在上一節開頭所說的,即聯合機率 \(P(d,h)\) 是通過將先驗機率 Pphq 乘以似然性 \(P(d|h)\) 計算出來的。 在現實生活中,我們實際上知道如何計算的是先驗機率和似然性,所以讓我們將它們代回方程式。 這給了我們後驗機率的以下公式:
\[P(h|d)=\\frac{P(d|h)P(h)}{P(d)}\]
女士們先生們,這個公式被稱為貝葉斯規則。它描述了一個學習者如何從對不同假設的合理性的先驗信念出發,並告訴您當面對數據時應如何修正這些信念。 在貝氏範例中,所有的統計推論都源自這個簡單的規則。
在翻譯過程中,我運用後退提問策略,比對原文與譯文,確認所有專有名詞均有翻譯。也檢查了是否存在需要保留不翻譯的特殊代碼,請檢閱翻譯初稿。
16.2 貝氏假設檢定
在 單元 9 中,我描述了正統的假設檢定方法。 這需要整整一章來描述,因為虛無假設檢定是一個非常精密的設備,人們覺得很難理解。 相反,貝氏假設檢定的方法簡直簡單得令人難以置信。 讓我們選擇一種與正統場景緊密類似的設置。 有兩個要比較的假設,虛無假設 \(h_0\) 和替代假設 \(h_1\)。 在運行實驗之前,我們對哪些假設是真實的有一些信念 \(P(h)\)。我們運行一項實驗並獲得數據 d。 與次數主義統計不同,貝氏統計允許我們討論虛無假設為真的機率。 更妙的是,它允許我們使用貝葉斯規則計算虛無假設的後驗機率:
\[P(h_0|d)=\frac{P(d|h_0)P(h_0)}{P(d)}\]
該公式準確地告訴我們在觀察到數據 d 後,我們對虛無假設應該有多大的信念。 類似地,我們可以使用基本相同的方程式確定對替代假設的信任程度。 我們所要做的只是更改下標:
\[P(h_1|d)=\frac{P(d|h_1)P(h_1)}{P(d)}\]
這非常簡單,以至於我覺得我連把這些方程寫下來都很傻,因為我所做的只是從前一節複製了貝氏規則。8
在翻譯過程中,我運用後退提問策略,比對原文與譯文,確認所有專有名詞均有翻譯。也檢查了是否存在需要保留不翻譯的特殊代碼,請檢閱翻譯初稿。
16.2.1 貝氏因子
在實踐中,大多數貝氏數據分析師傾向於不以原始後驗機率 \(P(h_0|d)\) 和 \(P(h_1|d)\) 的形式談論。相反,我們傾向於以後驗賠率比(Posterior odds)的形式談論。可以想像成下注。例如,假設虛無假設的後驗機率為25%,替代假設的後驗機率為75%。替代假設的機率是虛無假設的三倍,所以我們說賠率比為3:1,有利于替代假設。數學上,我們計算後驗賠率比所要做的就是將一個假設的後驗機率除以另一個假設的後驗機率
\[\frac{P(h_1|d)}{P(h_0|d)}=\frac{0.75}{0.25}=3\]
或者,用這一節開始提到的公式改寫成
\[\frac{P(h_1|d)}{P(h_0|d)}=\frac{d|h_1}{d|h_0} \times \frac{h_1}{h_0}\]
實際上,這個等式值得擴展。 這裡有三個不同的術語您應該知道。 在左側,我們有後驗賠率比,它告訴您在看到數據后對虛無假設和替代假設的相對合理性的信念。 在右側,我們有先驗賠率比(Prior odds),它指示您在看到數據之前的想法。在中間,我們有貝氏因子(Bayes factor),它描述了數據提供的證據量。 (表 16.9)。
| \(\frac{P(h_1|d)}{h_0|d}\) | \(=\) | \(\frac{P(d|h_1)}{d|h_0}\) | \(\times \) | \(\frac{P(h_1)}{h_0}\) |
| \(\Uparrow\) | \(\Uparrow\) | \(\Uparrow\) | ||
| Posterior odds | Bayes factor | Prior odds |
貝氏因子(有時縮寫為 BF)在貝氏假設檢定中佔有特殊地位,因為它在正統假設檢定中的 p 值起著類似作用。 貝氏因子量化了數據提供的證據力度,因此報告貝氏因子是人們在運行貝氏假設檢定時傾向於報告的內容。 報告貝氏因子而不是後驗賠率比的原因是不同的研究人員會有不同的先驗分布。有些人可能傾向於相信虛無假設為真,而其他人可能傾向於相信它為假。因此,禮貌的應用研究者應做的是報告貝氏因子。這樣,閱讀論文的任何人都可以將貝氏因子與自己的個人先驗賠率比相乘,並且他們可以自己算出後驗賠率比。無論如何,按照慣例,我們喜歡假裝我們給予虛無假設和替代假設同等考慮,在這種情況下,先驗賠率比等於1,後驗賠率比就等於貝氏因子。
16.2.2 解讀貝氏因子
貝氏因子的一個真正好處是這些數字本身就很有意義。如果您運行一項實驗並計算出貝氏因子為4,這意味著您的數據提供的證據對應於有利於替代假設的4:1的賭注比例。 然而,已經有一些嘗試量化在科學環境下被認為有意義的證據標准。最廣泛使用的兩個是來自 Jeffreys (1961) 和 Kass & Raftery (1995) 。在這兩者中,我傾向於更喜歡 Kass & Raftery (1995) 表,因為它更加保守。 所以在這裡它是(表 16.10)。
| Bayes factor | Interpretation |
| 1 - 3 | Negligible evidence |
| 3 - 20 | Positive evidence |
| 20 - 150 | Strong evidence |
| > 150 | Very strong evidence |
而且要老實說,我認為即使是 Kass & Raftery (1995) 的標準也有點太仁慈了。如果由我決定,我會將“積極證據”類別稱為“弱證據”。 對我來說,3:1 到 20:1 的任何範圍都只是“弱”或“溫和”的證據而已。 但這裡沒有硬性規定。什麼算作強或弱證據完全取決於您的保守程度以及您的社區在願意將一項發現標籤為“真”之前堅持的標準。
無論如何,請注意,如果貝氏因子大於1(即證據有利於替代假設),那麼上面列出的所有數字都是有意義的。 然而,與正統方法相比,貝氏方法的一個大的實際優勢是它還允許您量化虛無假設的證據。 當這種情況發生時,貝氏因子將小於1。 您可以選擇報告小於1的貝氏因子,但說實話,我覺得這很容易造成困惑。 例如,假設在虛無假設 \(h_0\) 下數據的似然性 \(P(d|h_0)\) 等於0.2,而在替代假設 \(h_1\) 下對應的似然性 \(P(d|h_1)\) 為 0.1。 使用上面給出的方程式,這裡的貝氏因子為
\[BF=\\frac{P(d|h_1)}{P(d|h_0)}=\\frac{0.1}{0.2}=0.5\]
如果逐字理解,這個結果告訴我們,支持替代假設的證據為 0.5:1。 我覺得這很難理解。 對我來說,把等式“上下翻轉”更有意義,並報告支持虛無假設的證據量。 換句話說,我們計算的是
\[BF' = \\frac{P(d|h_0)}{P(d|h_1)}=\\frac{0.2}{0.1}=2\]
而我們要報告的是 2:1 的貝氏因子支持虛無假設。更容易理解,並且可以使用上面的表來解釋。
16.3 為何需要貝氏統計
以下是翻譯初稿:
到目前為止,我一直專注於支撐貝氏統計的邏輯基礎。我們討論了“機率作為信念程度”的觀念以及它隱含的關於理性代理人應如何推理世界的內容。您必須自行回答的問題是:您希望如何進行統計學? 您想作為正統統計學家依靠抽樣分布和 p 值來指導您的決策? 還是您想作為一個貝氏主義者,依靠先驗信念、貝氏因子和有理性信念修正規則等? 老實說,我不能為您回答這個問題。 最終,這取決於您認為什麼是正確的。 這是您的決定,僅您一人的決定。 雖然如此,我可以談談我為什麼更喜歡貝氏方法。
16.3.1 統計學呈現你所相信的世界面貌
“您一直在使用那個詞。我不認為它意味著您認為的意思”
– 伊尼戈·蒙托亞,《公主新娘》9
對我來說,貝氏方法的最大優勢之一是它能夠回答正確的問題。 在貝氏框架內,提到“假設為真的機率”是完全合理和允許的。 您甚至可以嘗試計算這個機率。 最終,這難道不是您希望統計檢驗告訴您的嗎? 對於真正的人類而言,這似乎是做統計的全部重點,即確定什麼是真的什麼不是真的。 每當您不完全確定真相時,都應使用機率論的語言來說些“理論 A 為真的機率為 80%,但理論 B 為真的機率為 20%”之類的話。
對人類而言,這似乎非常明顯,但在正統框架中這明確被禁止了。 對次數主義者來說,這種陳述是無意義的,因為“理論是真實的”不是一個可重複的事件。一個理論要麼是真的,要麼是假的,不管您多麼希望做出這樣的機率陳述,都是不允許的。 這就是為什麼在 小單元 9.5 中我一再警告您不要將 p 值解釋為虛無假設為真的機率。這就是為什麼幾乎每本統計學教科書都不得不重複這一警告。 那是因為人們迫切希望這是正確的解釋。 儘管有次數主義教條,但終生教授本科生和每天進行數據分析的經驗告訴我,大多數實際的人類認為“假設為真的機率”不僅有意義,而且是我們最關心的事情。 這是一個非常吸引人的想法,甚至受過訓練的統計學家也會誤解試圖以這種方式解釋 p 值。例如,以下是 2013 年 Newspoll 官方報告中的一段話,解釋如何解釋他們的(次數主義)數據分析:10
在整個報告中,在相關的地方,已注意到統計上顯著的變化。所有顯著性測試都是基於 95% 的置信水平進行的。這意味著如果注意到一項變化在統計上顯著,那麼實際變化發生的機率為 95%,並且僅僅是由於機會變異引起的。(強調添加)
不!這不是 p < .05 的意思。對次數主義統計學家來說,95% 的置信水平也不是這個意思。加粗部分就是完全錯誤的。正統方法不能告訴您“實際變化發生的機率為 95%”,因為這不是次數主義機率可以分配給的事件類型。對於意識形態次數主義者來說,這句話應該是沒有意義的。即使您是更務實的次數主義者,它仍然是 p 值的錯誤定義。如果您想依賴正統統計工具,那麼這句話就根本不被允許或正確。
另一方面,假設您是貝氏主義者。儘管加粗通過是 p 值的錯誤定義,但當貝氏主義者說替代假設的後驗機率大於 95% 時,這幾乎正是他們的意思。 而這裡有一個問題。如果您實際上想報告的是貝氏後驗,那麼您為什麼還要嘗試使用正統方法呢? 如果您想做出貝氏主義者的認定,您所要做的就是成為貝氏主義者並使用貝氏工具。
就我個人而言,我發現切換到貝氏觀點最自由的就是這一點。 一旦您轉換了思維方式,您就不再需要圍繞 p 值的反直覺定義困惑您的大腦。 您不必費心記住為什麼您不能說您 95% 確定真值落在某個區間內。 您所要做的只是誠實地說出您在運行該研究之前的信念,然後報告您從中學到了什麼。 聽起來不錯,不是嗎? 對我來說,這就是貝氏方法的大前提。 您可以真正地做出您想要的分析,並表達您真正相信數據正在告訴您的內容。
16.3.2 你能相信的證據標準
如果 \(p\)低於.02,則強烈表明 \(null\) 假設無法解釋全部事實。如果我們在 .05 畫一條常規線,並認為更小的 \(p\)值表示真實的差異,我們通常不會犯太大的錯誤。
– 羅納德·費雪爵士 (Fisher, 1925)
考慮上述羅納德·費雪爵士的引文,他是當今正統統計方法的奠基人之一。 如果有人有資格表達對 p 值預期功能的意見,那就是費雪了。 在摘自他的經典指南《研究工作者的統計方法》的這段話中,他非常清楚地說明了什麼是在 p < .05 時拒絕虛無假設。 在他看來,如果我們認為 p < .05 意味著“真實效應”,那麼“我們通常不會犯太大的錯誤”。 這種觀點並不罕見。 根據我的經驗,大多數從業人員的觀點與費雪的觀點非常相似。 從本質上講,假定 p < .05 建議代表了相當嚴格的證據標准。
這是真的嗎?解決這個問題的一種方法是嘗試將 p 值轉換為貝氏因子,並查看兩者的比較情況。 這並不容易,因為 p 值與貝氏因子是一種基本不同的計算,它們不測量同樣的事情。 然而,已經有一些嘗試找出兩者之間的關係,而且有些令人吃驚。 例如,Johnson (2013) 提出了一個相當有說服力的論點,即(至少對於 t 檢驗)p < .05 的閾值大致對應於大約 3:1 到 5:1 之間的貝氏因子支持替代假設。 如果這是正確的,那麼費雪的說法有些牽強。 假設虛無假設一半時間為真(即 \(H_0\) 的先驗機率為 0.5),並使用這些數字計算在 p < .05 拒絕虛無假設時虛無假設的後驗機率。 使用 Johnson (2013) 的數據,我們看到如果您在 p ă .05 時拒絕虛無假設,那麼大約 80% 的時候您是正確的。 我不知道您怎麼看,但在我看來,一個確保您在 20% 的決策中會錯誤的證據標准還不夠好。 事實仍然是,與費雪的說法完全相反,如果您在 p < .05 時拒絕虛無假設,您確實會經常犯錯。 這根本不是一個非常嚴格的證據閾值。
16.3.3 p值只是幻象
– 出自電玩遊戲「傳送門」的迷因梗11
在這一點上,您可能會認為真正的問題不在於正統統計學,只在於 p < .05 的標準。在某種意義上,這是正確的。 Johnson (2013) 的建議並不是“現在每個人都必須成為貝氏主義者”。相反,建議是更明智的做法是將常規標準轉移到類似 p < .01 的水平。這不是一個不合理的觀點,但在我看來,問題比這更嚴重一些。在我看來,大多數(但不是全部)正統假設檢定所構建的方式中存在一個相當大的問題。它們在研究人員如何進行研究方面極為天真,因此大多數 p 值都是錯誤的。
聽起來像一個荒謬的說法,對嗎?好吧,思考一下以下情景。您提出了一個非常激動人心的研究假設,並設計了一項研究來測試它。您非常勤奮,所以您運行了功效分析以確定樣本量應該是多少,並進行了研究。您運行了您的假設檢定,跳出了一個 p 值為 0.072。真他媽的令人惱火,不是嗎?
您應該怎麼做?以下是一些可能性:
您得出結論認為沒有效應並嘗試將其作為無效果結果發表
您猜測可能存在效應並嘗試將其作為“邊緣顯著”結果發表
您放棄並嘗試新的研究
您收集更多數據以查看 p 值是否上升或(更好的是!)下降至“魔力”標准 p < .05 以下
你會選哪一個? 在繼續閱讀之前,我強烈建議您花些時間思考一下。 跟自己誠實。 但不要為此費太多心思,因為無論您選擇什麼,您都是搞砸了。 基於我作為作者、評審員和編輯的親身經歷,以及我從其他人那裡聽到的故事,以下是每種情況下會發生的事情:
讓我們從選項 1 開始。如果您嘗試將其作為無效果結果發表,論文的發表將會困難重重。一些評審員會認為 p = .072 並不是真的無效果。他們會認為這是邊緣顯著。其他評審員會同意這是無效果,但會聲稱儘管某些無效果結果是可以發表的,但您的研究不是。一兩個評審員甚至可能站在您這邊,但您在讓論文獲得接受方面將面臨一場苦戰。
好的,讓我們考慮選項 2。假設您嘗試將其作為邊緣顯著結果發表。一些評審員會聲稱這是無效果並不應該發表。其他人會聲稱證據不明確,並且您應該收集更多數據直到獲得明確的顯著結果。同樣,發表過程並不青睞您。
鑑於發表像 p = .072 這樣的“模糊”結果的困難,選項 3 似乎很誘人:放棄並做點其他的事情。但這是職業自殺的計劃。如果您每次面對模糊時都放棄並嘗試新的項目,那麼您的工作永遠不會被發表。如果您在學術領域沒有發表記錄,您可能會失去工作。因此該選項被排除。
看起來您只剩下選項 4 了。您沒有決定性的結果,所以您決定收集更多數據並重新運行分析。看起來很合理,但不幸的是,如果您這樣做,那麼您所有的 p 值現在都是不正確的。全部都是。不僅僅是您為這項研究計算的 p 值。全部都是。您過去計算的所有 p 值以及您將來計算的所有 p 值。幸運的是,沒有人會注意到。您將得到發表,而且您撒謊了。
等等,什麼?最后一部分怎麼可能是真的?我的意思是,這聽起來像一個非常合理的策略,不是嗎?您收集了一些數據,結果並不確定,所以現在您想要做的就是收集更多數據直到結果確定。這有什麼問題嗎?
誠實地說,這沒有任何問題。這是一個合理的、明智的和理性的做法。在現實生活中,這正是每個研究人員所做的。不幸的是,如我在 單元 9 中描述的虛無假設檢定理論禁止您這樣做。12 原因是理論假設實驗已經結束並且所有的數據已經收集完畢。並且因為它假設實驗已經結束,它只考慮兩種可能的決策。如果您使用常規的 p < .05 標準,這些決策如 表 16.11 所示。
| Outcome | Action |
| p less than .05 | Reject the null |
| p greater than .05 | Retain the null |
您正在做的是向決策問題添加第三種可能的行動。具體來說,您正在使用 p 值本身作為繼續該實驗的理由。因此,您將決策過程轉變為更類似于 表 16.12 的過程。
基于初步測試中獲得的 p 值繼續收集數據。
| Outcome | Action |
| p less than .05 | Stop the experiment and reject the null |
| p between .05 and .1 | Continue the experiment |
| p greater than .1 | Stop the experiment and retain the null |
我在 單元 9 中描述的虛無假設檢定的“基本”理論並沒有建立來處理這類事情。如果您是在現實生活中會選擇“收集更多數據”的那類人,這意味著您并沒有按照虛無假設檢定的規則進行決策。即使您碰巧與假設檢定得出相同的決定,您也沒有遵循其所暗示的決策過程,這种過程違規正是導致問題的原因。13 您的 p 值只是幻覺。
更糟糕的是,它們以一種危險的方式撒謊,因為它們都_太小_了。為了讓您感受一下這有多嚴重,請考慮以下(最壞)情況。假設您是一位預算十分緊張的超級熱心的研究員,完全沒有注意我上面的警告。您設計了一項比較兩組的研究。您迫切希望在 \(p < .05\) 水平上看到顯著結果,但您真的不想收集比需要的更多數據(因為這很昂貴)。為了節省成本,您開始收集數據,但每次有新的觀察值到來時,您都會對數據運行 t 檢驗。如果 t 檢驗說 \(p < .05\),那麼您停止實驗並報告顯著結果。如果不是,您會繼續收集數據。您會一直這樣做,直到達到實驗的預定花費限額。假設該限制在 \(N = 1000\) 的觀察上觸發。事實證明,真相是沒有真正的效應:虛無假設為真。所以,您達到實驗結束並(正確地)得出沒有影響的結論的機率是多少?在理想的世界中,答案在此應該是 95%。畢竟,\(p < .05\) 標准的全部要點是將型I錯誤率控制在 5% 左右,所以我們希望的就是在這種情況下錯誤拒絕虛無假設的機率只有 5%。然而,沒有保證這將是真的。您是在破壞規則。因為您反复運行測試,“偷看”數據以查看是否獲得了顯著結果,所以所有賭注都打消了。
那麼情況究竟有多糟糕呢?答案如 圖 16.1 中實線所示,這是驚人的糟糕。如果您在每個單獨的觀察后查看數據,您將有 49% 的可能性會產生型I錯誤。也就是說,嗯,這比應該的 5% 大得多。相比之下,設想您使用了以下策略。開始收集數據。每次觀察到達時,運行 貝氏t檢定 並查看貝氏因子。我假設 Johnson (2013) 是正確的,並且我會將 3:1 的貝氏因子大致視為等同於 p 值為 .05。14 這次,我們的扣發狂研究人員使用以下過程。如果貝氏因子大於或等於 3:1 支持虛無假設,則停止實驗並保留虛無假設。如果它大於或等於 3:1 支持替代假設,則停止實驗並拒絕虛無假設。否則繼續測試。現在,就像上次一樣,假設虛無假設為真。會發生什麼?實際上,我也為此情況運行了模擬,結果如圖 圖 16.1 中的虛線所示。結果報表明,I 型錯誤率遠遠低於使用正統 t 檢驗獲得的 49%。
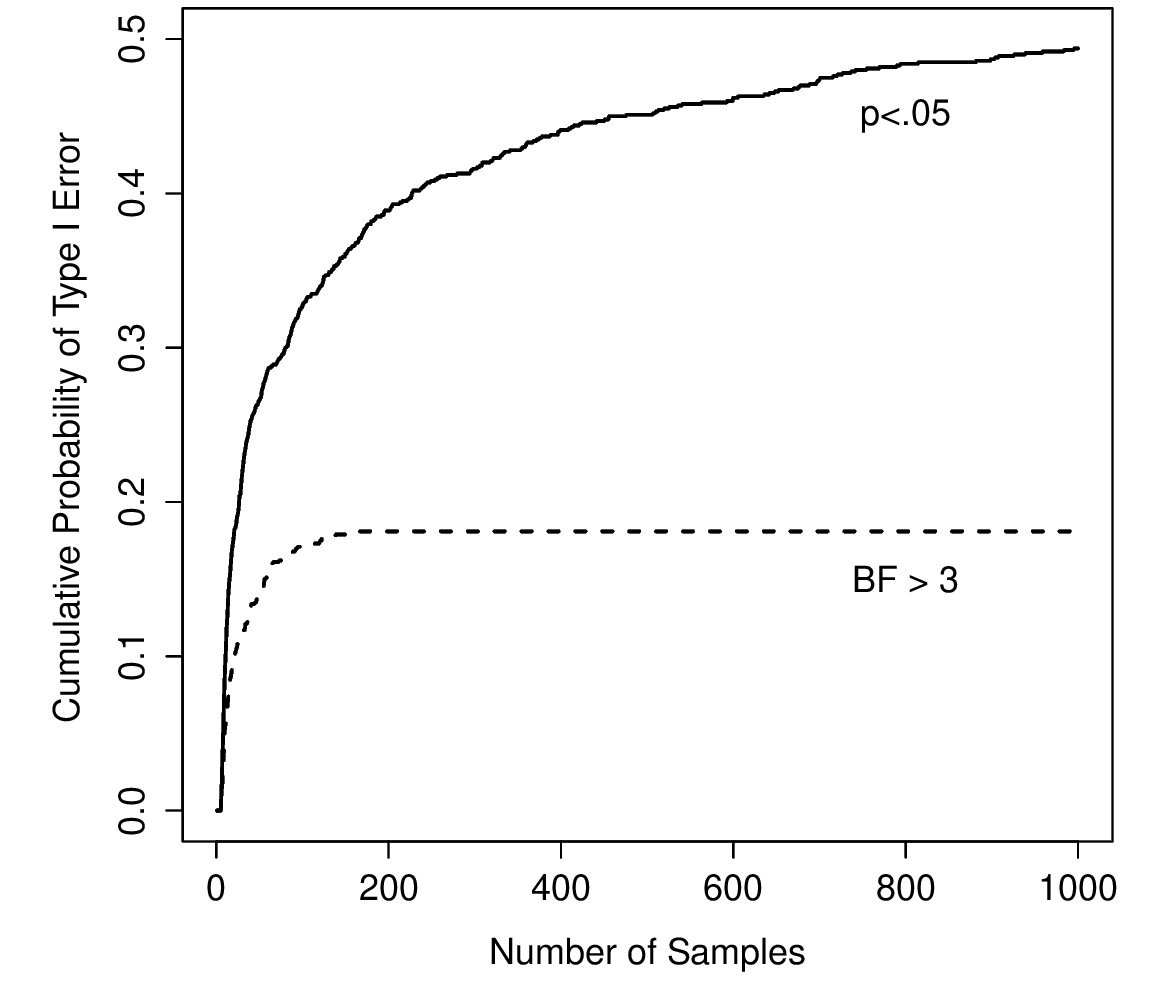
在某種意義上,這很令人驚訝。正統虛無假設檢定的全部重點是控制型I錯誤率。貝氏方法實際上根本沒有設計來做這件事。然而,事實證明,當面對一個不斷運行假設檢定的“扳機快”研究人員時,貝氏方法更加有效。即使是大多數貝氏主義者認為可以接受的寬鬆 3:1 標準,也比 p < .05 規則更安全。
16.3.4 顯著性檢定真的有那麼糟嗎?
在上一節中給出的例子是一種相當極端的情況。在現實生活中,人們不會在每次有新觀察值到達時運行假設檢定。所以說 p < .05 標準“實際上”對應 49% 的型I錯誤率(即 \(p = .49\))並不公平。但事實仍然是,如果您想要您的 p 值是誠實的,那麼您要麼需要切換到一種完全不同的假設檢定方法,要麼執行嚴格的不偷看規則。您不允許使用數據來決定何時終止實驗。您不允許查看“邊緣” p 值並決定收集更多數據。您甚至不允許在查看數據后更改數據分析策略。您嚴格要求遵循這些規則,否則您計算的 p 值將是無意義的。
而且是的,這些規則出人意料地嚴格。幾年前的一次課堂練習中,我要求學生考慮這種情況。假設您開始運行研究,意圖收集 \(N = 80\) 人。 當研究開始時,您遵循規則,拒絕查看數據或運行任何測試。 但是當您達到 \(N = 50\) 時,您的意志力屈服了……您偷看了一眼。 猜猜怎麼著? 您得到了顯著結果! 現在,當然,您知道您說過您會繼續運行研究,樣本量為 \(N = 80\),但現在這似乎有點毫無意義,不是嗎? 當樣本量為 \(N = 50\) 時結果就是顯著的,所以繼續收集數據豈不是浪費和低效嗎? 您不會感到誘惑停下來嗎?就是一點點? 請記住,如果您這樣做了,您在 \(p < .05\) 水平上的型I錯誤率剛剛膨脹到了 8%。 當您在論文中報告 \(p < .05\) 時,您真正在說的是 \(p < .08\)。 這就是“只偷看一眼”的後果可能會有多糟。
現在考慮一下。 科學文獻中充滿了 t 檢驗、方差分析、回歸和卡方檢驗。 當我寫這本書的時候,我並沒有隨意選擇這些測試。 出現在大多數入門統計教科書中的這四種工具的原因是它們是科學的主要工具。 這些工具中沒有一個包括處理“查看數據”的校正:它們都假定您不這樣做。 但這個假設有多現實呢? 在現實生活中,您認為在實驗結束前有多少人“查看”過數據並在看到數據的樣子后調整了后續行為呢? 除非採樣過程受外在約束的限制,否則我猜答案是“大多數人都這樣做過”。如果發生這種情況,您可以推斷報告的 p 值是錯誤的。 更糟糕的是,因為我們不知道他們實際遵循的決策過程,我們無從知道 p 值本該是麼。 如果不知道研究人員使用的決策制定過程,則無法計算 p 值。 所以報告的 p 值仍然在撒謊。
鑑於上述所有內容,結論是麼呢? 並不是貝氏方法天衣無縫。如果一個研究者決心欺騙,他們總是可以這樣做的。 貝葉斯規則無法阻止人們撒謊,也無法阻止他們操縱實驗。 這不是我在此要論述的要點。 這個論點與本書一開始就強調的一樣:我們運行統計檢驗的原因是為了防止我們遭受自身的傷害。(見 小單元 1.1 ) 而“查看數據”之所以這麼令人擔憂的是因為它非常誘人,即使對誠實的研究人員也是如此。 推論理論必須承認這一點。 是的,您可能會通過說研究人員沒有正確使用它們來為 p 值辯護,但在我看來,這遺漏了重點。 一種統計推論理論如果對人類的了解是如此天真,甚至不考慮研究人員可能會查看自己的數據的可能性,那麼這種理論就不值得擁有。 從本質上講,我的論點是:
好的法律起源於不良道德。
– 安布羅西烏斯·馬克羅比烏斯 15
良好的統計檢驗規則必須承認人性軟弱。 我們所有人都有罪。我們所有人都面臨誘惑。 一個良好的統計推論系統應該仍然有效,即使它是由真實的人使用的。 正統虛無假設檢定並未做到這一點。 16
16.4 貝氏t檢定
本書中討論的一種重要的統計推論問題是比較兩個均值,在 單元 11 t檢定部分有詳細討論。如果您還記得那麼遠的內容,您會回憶起有幾種t檢定的版本。在本節中,我將稍微談論獨立樣本t檢定和配對樣本t檢定的貝氏版本。
16.4.1 獨立樣本t檢定
最常見的t檢定是獨立樣本t檢定,當您擁有類似於我們在 單元 11 t檢定部分使用的harpo.csv數據集的數據時就會出現。在這個數據集中,我們有兩組學生,那些接受Anastasia授課的學生和那些跟Bernadette上課的學生。我們要回答的問題是這兩組學生獲得的成績是否有任何區別。 在 單元 11 ,我建議您可以使用jamovi中的獨立樣本t檢定分析這種數據,它給我們 圖 16.2 的結果。由於我們獲得了小於0.05的p值,我們拒絕了虛無假設。
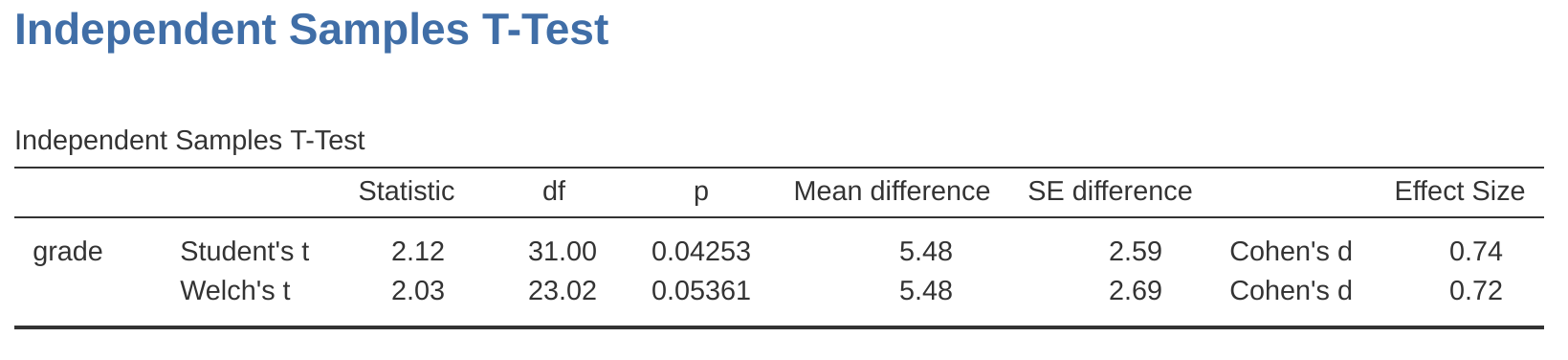
那麼貝氏t檢定看起來是什麼樣子呢?我們可以通過在“測試”選項下選擇“貝氏因子”複選框並接受對“先驗”的建議默認值來獲得貝氏因子分析。這給出了 圖 16.3 表格中顯示的結果。我們在這個表中得到的貝氏因子統計量為1.75,這意味著這些數據提供的證據大約以1.8:1的比率支持替代假設。
在繼續之前,有必要強調正統檢驗結果和貝氏檢驗結果之間的區別。根據正統檢驗,我們獲得了顯著結果,儘管只是勉强顯著。儘管如此,很多人會很高興地接受p = .043作為效應的合理有力的證據。相比之下,請注意,貝氏檢驗甚至沒有達到2:1的比率支持效應,最多被認為是非常弱的證據。根據我的經驗,這是一個非常典型的結果。在拒絕虛無假設之前,貝氏方法通常需要更多的證據。

16.4.2 相依樣本t檢定
在 小單元 11.5 ,我討論了chico.csv數據集,其中測量了學生在兩個測試中的成績,我們有興趣了解從測試1到測試2的成績是否有所提高。因為每個學生都參加了兩次測試,所以我們使用的數據分析工具是相依樣本t檢定。 圖 16.4 顯示了jamovi結果報表,傳統的成對t檢定結果與貝氏因子分析並列。在這一點上,我希望您可以毫不費力地讀取這個輸出。數據提供了大約6000:1的證據支持替代假設。我們可能可以非常自信地拒絕虛無假設!

16.5 本章小結
本章前半部主要討論貝氏統計學的理論基礎。理性者的機率推論這一節介紹貝氏推論的數學推導,接著概述貝氏假設檢定。然後我在為何需要貝氏統計說明希望同學學習貝氏統計的理由。
後半部是實例說明及演練貝氏t檢定。如果同學想知道更多貝氏統計,市面上已經有許多好書問世,等著你去研讀學習。 Kruschke (2011) 撰寫的教科書實作貝氏資料分析(Doing Bayesian Data Analysis)結合理與實作範例,是不錯的第一選擇17。這本書並非以本章介紹的”貝氏因子”介紹具氏統計,所以你不必充分了解本章內容也能閱讀學習。如果是對認知心理學有興趣的同學,應該要找 Lee & Wagenmakers (2014) 的教科書做為進階學習。原作者推薦以上兩本是因為作者的專長領域相近,還有許多不同領域學者所撰寫的貝氏統計教科書或教程,有心學習的同學請好好留意。
我知道,這需要一定的信任,但讓我們繼續吧,好嗎?↩︎
噢。我很不願意提起這一點,但一些統計學家會反對我在這裡使用“似然性”一詞。問題在於,“似然性”在次數主義統計中有非常具體的含義,而且與它在貝氏統計中的含義不完全相同。據我所知,貝葉斯最初沒有任何公認的名稱來表示似然性,所以人們使用次數主義術語成為常規做法。這本不會成為問題,除非事實證明貝葉斯使用這個詞的方式與次數主義者的方式相當不同。這裡不是再來一堂冗長的歷史課的地方,但粗略地說,當貝葉斯說“一個似然函數”時,他們通常是指表中的一行。當次數主義者說同樣的事情時,他們指的是同一個表,但對他們來說,“一個似然函數”幾乎總是指的是其中一列。這種區別在某些語境中很重要,但對我們的目的來說並不重要。↩︎
為明確起見,“先驗”信息是預先存在的知識或信念,在我們收集或使用任何數據來改善該信息之前。↩︎
如果我們更複雜一些,我們可以擴展示例以容納我撒謊關於雨傘的可能性。但讓我們保持簡單,可以嗎?↩︎
您可能會注意到,這個方程式實際上是我在上一節開頭列出的同一個基本規則的重述。 如果您將等式兩邊都乘以 \(P(d)\),那麼您得到 \(P(d)P(h|d)=P(d,h)\),這是聯合機率的計算規則。 所以我在這裡實際上並沒有引入任何“新的”規則,我只是以不同的方式使用了相同的規則。↩︎
顯然,這是一個高度簡化的故事。 真實世界中貝氏假設檢定的所有複雜性都歸結為當假設 h 是一个複雜且模糊的事物時如何計算似然性 \(P(d\|h)\)。 我不打算在這本書中討論這些複雜性,但我確實想要強調,儘管這個簡單的故事在目前是正確的,但現實生活比我能夠在入門統計教科書中涵蓋的要複雜得多。↩︎
http://www.imdb.com/title/tt0093779/quotes 。我應該指出,我不是第一個使用這句話來抱怨次數學派方法的人。Rich Morey和他的同事們首先有了這個想法。我厚顏無恥地偷了它,因為在這種情況下使用它是個非常棒的引文,而且我絕不會錯過任何引用《公主新娘》的機會。↩︎
http://about.abc.net.au/reports-publications/appreciation-survey-summary-report-2013/↩︎
為了完全誠實,我應該承認並非所有正統統計檢驗都依賴這個愚蠢的假設。有時在臨床試驗等中會使用一些序列分析工具。這些方法建立在假設數據在到達時即進行分析的基礎上,並且這些檢驗在本章中指出的方式中沒有嚴重失誤。然而,序列分析方法的構建與“標準”版虛無假設檢定截然不同。它們沒有進入任何介紹教科書,在心理學文獻中也很少使用。我在此提出的問題對我目前介紹的每一種正統檢驗和我在文獻中看到的幾乎每一種檢驗都是有效的。↩︎
一張漫畫解釋這裡談的問題: http://xkcd.com/1478/ .↩︎
有些讀者可能會質疑為什麼我選擇 3:1 而不是 5:1,因為 Johnson (2013) 建議 \(p = .05\) 落在這個範圍內。我這樣做是為了給 p 值一個好處。如果我選擇 5:1 的貝氏因子,結果對於貝氏方法來說會看起來更好。↩︎
好吧,我知道一些知識豐富的次數主義者會讀這個部分並開始抱怨。 看,我又不傻。 我絕對知道,如果您採用序列分析的角度,您可以在正統框架內避免這些錯誤。 我也知道您可以明確設計考慮過期中分析的研究。 所以是的,從某種意義上說,我正在攻擊正統方法的“稻草人”版本。 然而,我所攻擊的稻草人是幾乎每一個從業者都在使用的版本。 如果有朝一日序列方法在實驗心理學家中成為規範,當我不再被迫每天閱讀 20 個極其可疑的方差分析時,我保證我會重寫這一節並減少苦澀。 但是在那一天到來之前,我堅持我的說法,即默認的貝氏因子方法在面對現實世界中存在的數據分析實踐中,具有更強的穩健性。 默認的正統方法很糟糕,我們都知道。↩︎
台灣同學可以找旗標出版社出版的〈AI必須! 從做中學貝氏統計〉做為自學材料。這本書援引John Kruschke的說明方式,介紹各種貝氏統計方法理論細節及運算方法。↩︎