11 比較單一與兩組平均值
單元 10 討論的檢定方法適用於依變項是名義尺度,獨變項也是名義尺度的資料。現實世界的許多研究問題都是要處理這種資料,所以卡方檢定的用途非常廣泛。然而,現實統計問題更有可能遇到的資料是,依變項為等距尺度或者更高階的連續尺度,研究目標是比較兩個獨立組之間的依變項平均值。例如,某位心理學家想知道有小孩的夫婦焦慮程度會不會比沒小孩的夫婦更高,或者相對於不聽音樂的人們,聽音樂會不會降低人們的工作記憶容量。閱讀一篇醫學論文,我們會想知道一種新藥物會不會增加或降低血壓。某位農業研究人員也許想知道磷肥會不會造成澳大利亞原生植物枯萎死亡。1就這些問題來說,依變項都是一種連續的、等距尺度或比例尺度變項,獨變項則是一種二元的「分組」變項。也就是說,處理資料的研究人員想比較兩組平均值的差異。
比較平均值的標準推論統計方法是 t 檢定,至於要使用那種t檢定則取決於問題內容。因此,本章重點是介紹各種類型的 t 檢定:單一樣本 t 檢定、獨立樣本 t 檢定和相依樣本 t 檢定。每種檢定方法都會討論單側與雙側檢定,還有 t 檢定的標準效果量 Cohen’s d。每個t檢定最後還有討論適用條件,以及可能違反這些條件時的補救方法。但是,在介紹t檢定之前,我們先介紹一下 z 檢定。
11.1 單一樣本z檢定
這一節要介紹統計學裡最無用的一種統計檢定方法:z 檢定。嚴格來說,這種檢定方法幾乎沒什麼研究人員會使用。學習z檢定的真正用途是,這個方法是學習 t 檢定前相當方便的墊腳石,但是 t 檢定可能是最被過度使用的統計學工具。
11.1.1 使用z檢定前的注意事項
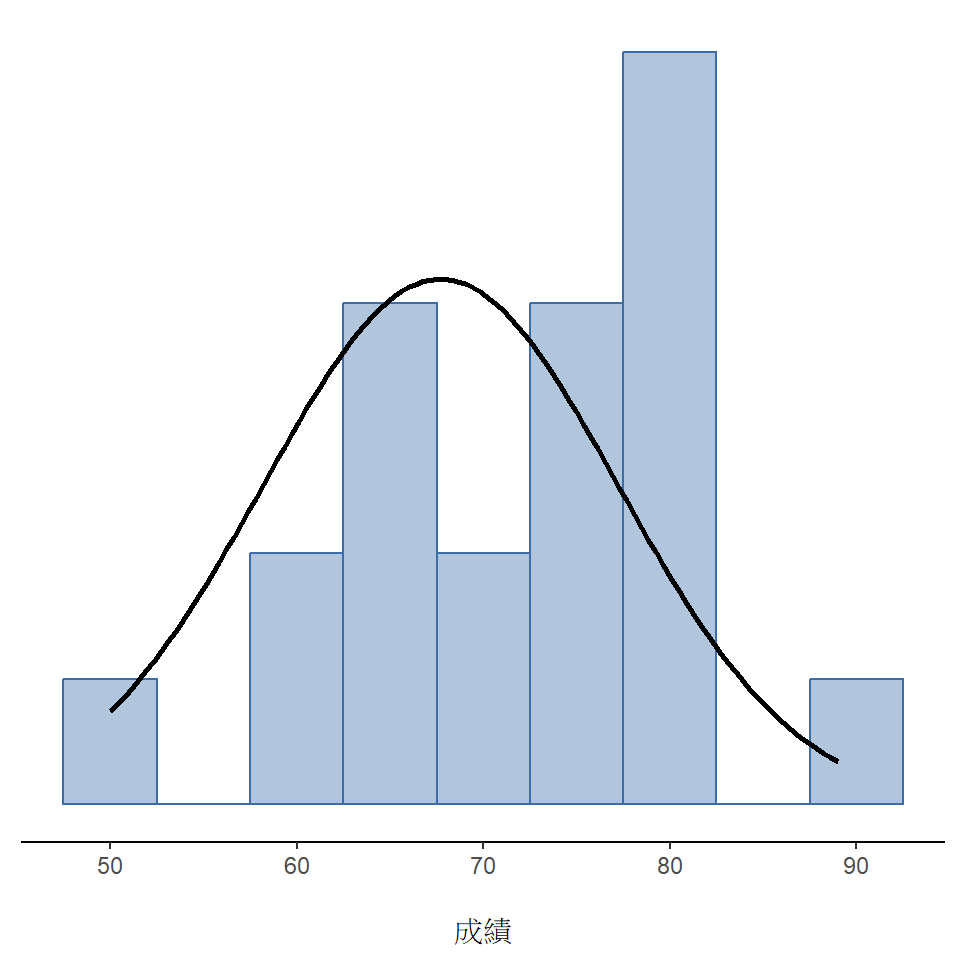
我們先用一個簡單的例子介紹 z 檢定如何運作的概念:我有一位朋友 Zeppo 老師準備按照常態分佈曲線為他的基礎統計學課程修課學生打分數。假如這門課程的平均分數是 \(67.5\),標準差是 \(9.5\),修課學生有數百人,其中有 20 位還修了心理學課程。出於好奇心,我想知道這些學生的成績是否與其他學生的成績一致,也就是這20位學生的平均分數也是 \(67.5\),還是他們的成績比全體平均分數更高或更低?這些學生的成績存於Zeppo老師分享給我的 zeppo.csv 資料檔(lsj資料集Zeppo),開啟 jamovi 的 ‘Exploration’ - ’Descriptives’的設定視窗,按照 單元 4 學過的方法,就能得到平均值為 \(72.3\)。2
50 60 60 64 66 66 67 69 70 74 76 76 77 79 79 79 81 82 82 89
看起來有修心理學課程的學生成績比全部同學的好一些。樣本平均值 \(\bar{X}=72.3\) 比假設的母群平均值 \(\mu=67.5\) 要高了不少分,但是,樣本量 \(N=20\) 其實並不是很大,也許這只是純粹的巧合。
為了能做出合理的評估,寫出我所知道的細節能幫助讀者了解。首先知道的是樣本平均值為 \(\bar{X}=72.3\),如果我相信這20位學生的標準差與班上其他學生的標準差相同,那麼母群標準差就是 \(\sigma=9.5\)。同時我還相信 Zeppo 老師是按常態分佈曲線給分,這20位學生的成績分佈也應該符合常態分佈。
接著我要具體呈現如何從資料取得能做判斷的資訊。我對此問題的假設可用這20位學生來源母群平均值 \(\mu\) 表示,而這個值是未知的。在有資料的當下,我想知道是不是 \(\mu=67.5\) ?因為這是我目前所知道的,需要設定一個假設檢定程序來解答這個問題。樣本資料以及可能的來源母群分佈顯示在 圖 11.1 。畫出統計圖還不能解答我的問題嗎? 現在需要學習更進一步的統計知識了。
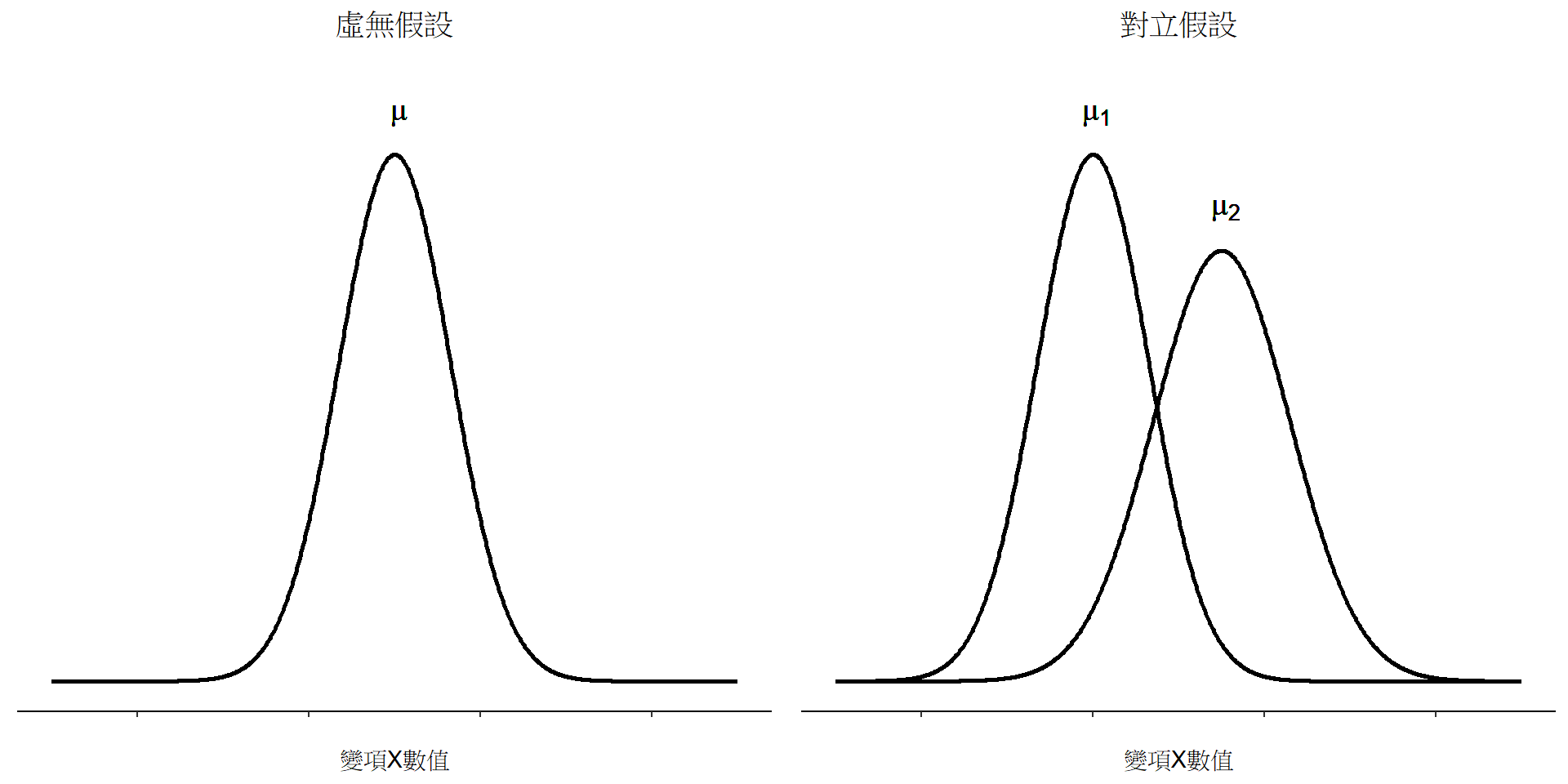
11.1.2 z檢定的統計假設
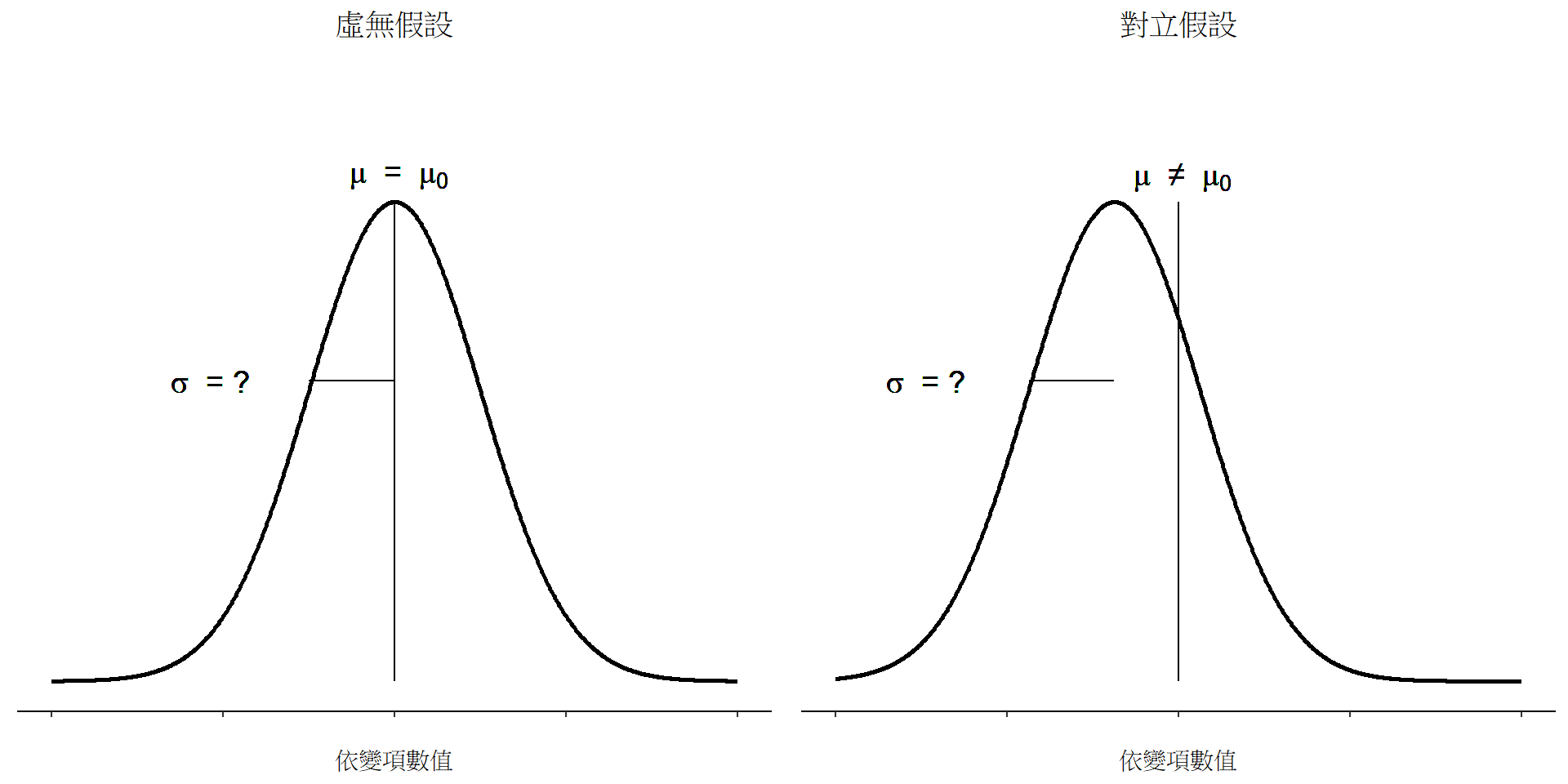
假設檢定的第一步是確定虛無假設和對立假設分表是代表什麼結果,以這個問題來說不難了解。這裡的虛無假設 \(H_0\) 是,心理系學生的成績母群平均值 \(\mu\) 等於 \(67.5\%\),對立假設是母群平均值不等於 \(67.5\%\)。若是用數學符號表示,這些假設的白話說明就變成了:
\[ H_0:\mu= 67.5 \] \[ H_1:\mu \neq 67.5 \]
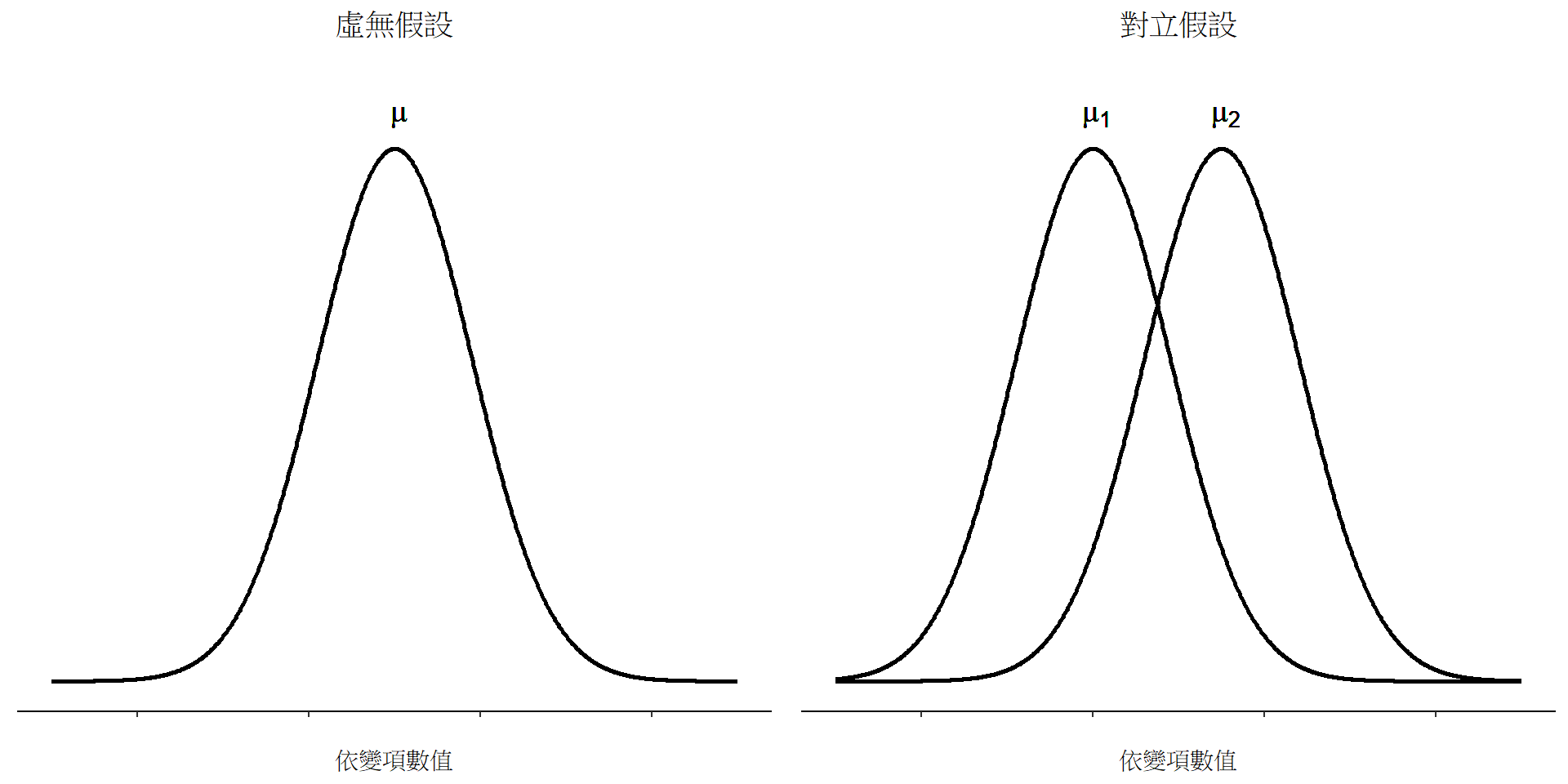
不過,使用數學記號表示,其實不大能讓大家更好理解統計假設,這只是呈現完成資料分析後會得到什麼簡記方法。要被檢定的虛無假設 \(H_0\) 和對立假設 \(H_1\) 的視覺圖像都呈現在 圖 11.2 。配合上一段的背景說明,視覺圖像除了能我們了解統計假設的重點在於結果是符合那個平均值(或者說期望值),還有提供一些有用的資訊,特別是以下兩點::
- 20位學生成績分佈符合常態分佈。
- 20位學生成績分佈的真實標準差 \(\sigma\) 等於 9.5。
我們暫時先將這些條件當成是絕對沒錯的事實,許多現實世界的研究問題,這類絕對可信的背景條件通常是不可能成立的。若是要靠這些條件執行假設檢定,只能當做所有條件都是成立的。要確認這些條件是否成立,其實需要做些檢查程序,只是為了方便解說z檢定程序,目前先暫時跳過。

接下來是設定一個可靠的檢定統計量,用來診斷成績分佈是符合\(H_0\) 還是 \(H_1\)。因為兩種假設都與母群平均值 \(\mu\)有關,樣本平均值 \(\bar{X}\)是我們能用來檢定的絕佳參考點,也就是計算樣本平均值 \(\bar{X}\) 與虛無假設預測的母群平均值之間的差異,在這個例子是 \(\bar{X} - 67.5\)。若要類推到同樣的分析問題,以\(\mu_0\) 代指虛無假設主張的母群平均值,這樣一來要計算的就是
\[\bar{X}-\mu_0\]
如果這個差異值等於或非常接近於0,虛無假設似乎是可接受的結論。如果這個差異值完全不等於0,那麼虛無假設似乎不太可能是有意義的結論。不過,這個差異離0多遠才有可能拒絕 \(H_0\) 呢?
為了搞清楚,我們需要耍一點小手段,就是之前提到的樣本資料服從常態分佈,以及母群標準差 \(\sigma\) 的值是已知的。若是成績分佈確實符合虛無假設,真正的平均值確實是 \(\mu_0\),這些事實支持母群分佈是平均值為 \(\mu_0\),標準差為 \(\sigma\) 的常態分佈。3
好啦,若真的那麼順利, \(\bar{X}\) 的分佈能告訴我們什麼事情呢?根據 小單元 8.3.3 討論過的中央極限定理,平均數 \(\bar{X}\) 的取樣分佈也是常態分佈,並且等於母群平均值 \(\mu\)。只是這個取樣分佈的標準差 \(se(\bar{X})\)–也被稱為平均值的標準誤差–真面目是4
\[se(\bar{X})=\frac{\sigma}{\sqrt{N}}\]
讓我們進一步了解這個技巧。運用 小單元 4.5 學過的標準分數,樣本平均數 \(\bar{X}\)可以轉換成標準分數,因為通常被寫成z,這裡可以改寫為 \(z_{\bar{X}}\)。改寫符號是為了方便記住,這裡正在計算的是樣本平均值的標準分數,不是單一觀察值的標準分數。如此一來,樣本平均值的 z 分數
\[z_{\bar{X}}=\frac{\bar{X}-\mu_0}{SE(\bar{X})}\]
也可以寫成
\[z_{\bar{X}}=\frac{\bar{X}-\mu_0}{\frac{\sigma}{\sqrt{N}}}\]
這個 z 分數就是這裡要用的檢定統計值,使用這個檢定統計值的好處是,像所有 z 分數一樣,它符合標準常態分佈:5
\[z_{\bar{X}} \sim Normal(0,1) \]
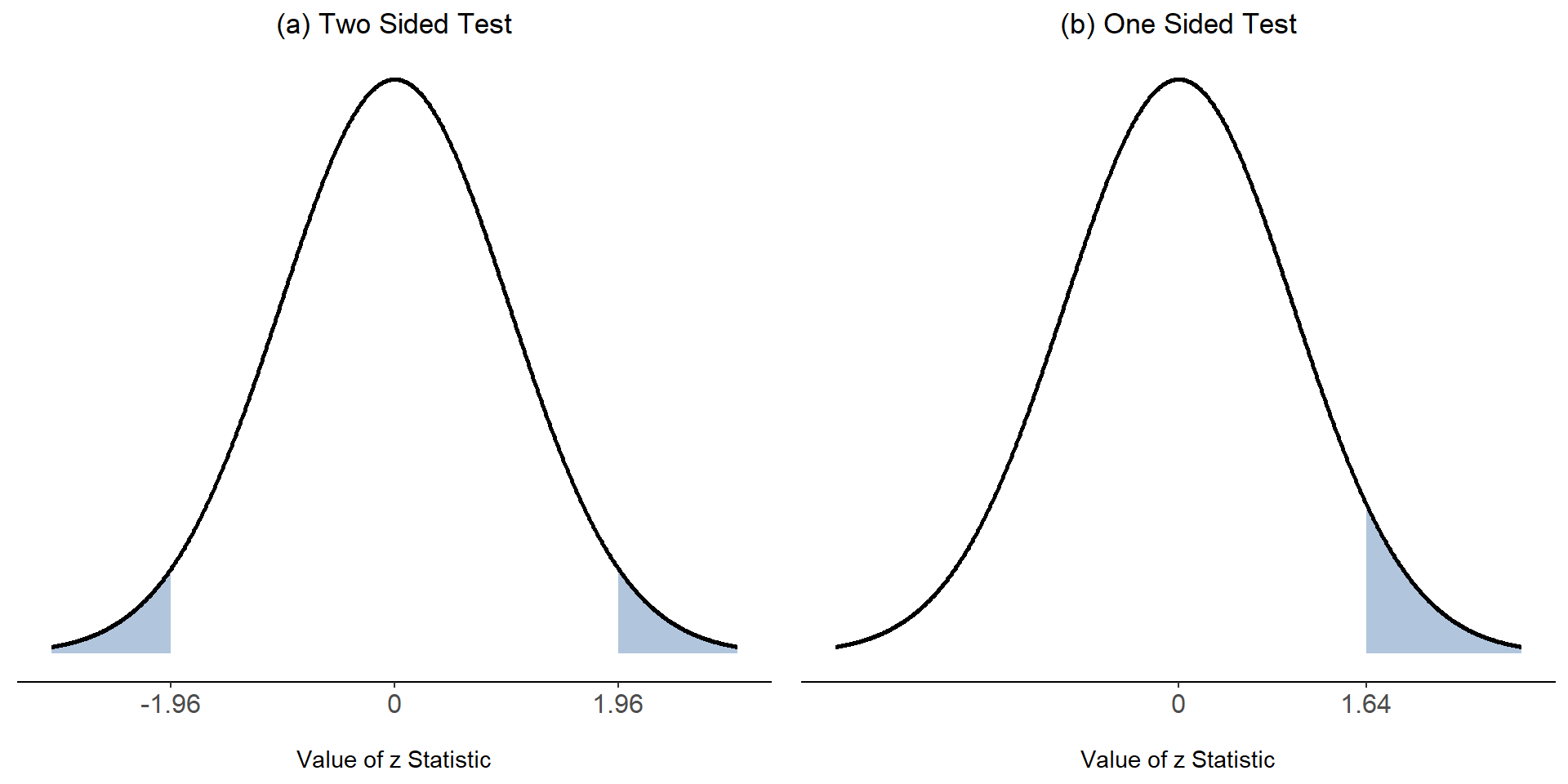
換句話說,無論原始資料的測量尺度是什麼,解讀z統計值的方法都是一樣的:z值代表觀察到的樣本平均值 \(\bar{X}\) 與虛無假設預測的母群平均值 \(\mu_0\)相差了多少標準誤。更棒的是,無論原始分數的母群參數是多少,z 檢定的 5% 棄絕域始終不變,如同 圖 11.3 的圖解。所以在以前大多數研究者和學生都要用手算統計的時代,可以從 表 11.1 找出要報告的p值。也可以反過來使用手算得出的z統計值,從教科書的附表找出臨界值。
| critical z value | ||
|---|---|---|
| desired \(\alpha\) level | two-sided test | one-sided test |
| .1 | 1.644854 | 1.281552 |
| .05 | 1.959964 | 1.644854 |
| .01 | 2.575829 | 2.326348 |
| .001 | 3.290527 | 3.090232 |
11.1.3 手作z檢定
現在,正如我之前提到的,z-test在實際應用中幾乎從不使用。這個測試在實際生活中如此罕見,以至於jamovi的基本安裝不包含內置功能。然而,這個測試是如此地簡單,以至於手動進行這個測試非常容易。讓我們回到Dr Zeppo課程的資料。在載入成績資料後,我需要做的第一件事是計算樣本均值,我已經做到了(\(72.3\))。我們已經有了已知的母群標準差(\(\sigma = 9.5\)),虛無假設所指定的母群平均值(\(\mu_0 = 67.5\))的值,以及樣本大小(\(N=20\))。
接下來,讓我們計算(真實)標準誤(可輕鬆用計算機完成):
\[ \begin{split} sem.true & = \frac{sd.true}{\sqrt{N}} \\\\ & = \frac{9.5}{\sqrt{20}} \\\\ & = 2.124265 \end{split} \]
最後,我們計算我們的z分數:
\[ \begin{split} z.score & = \frac{sample.mean - mu.null}{sem.true} \\\\ & = \frac{ (72.3 - 67.5)}{ 2.124265} \\\\ & = 2.259606 \end{split} \]
此時,我們會傳統地在臨界值表中查詢 \(2.26\) 的值。我們原來的假設是雙邊的(我們對心理學生在統計學上表現得比其他學生好或差沒有任何理論基礎),因此我們的假設檢驗也是雙邊的(或者是兩尾的)。從我先前顯示的小表中,我們可以看到 \(2.26\) 大於需要在 \(\alpha = .05\) 的顯著性水平下具有顯著性的臨界值 \(1.96\),但小於需要在 \(\alpha = .01\) 的水平下具有顯著性的值 \(2.58\)。因此,我們可以得出結論,我們可以這樣寫:
在心理學學生的樣本中,平均成績為 \(73.2\),假定真正的人口標準差為 \(9.5\),我們可以得出結論,心理學學生在統計學上的得分與課程平均分有顯著差異(\(z = 2.26, N = 20, p<.05\))。
11.1.4 z檢定的適用條件
正如之前的單元,所有統計檢定皆建立於特定的適用條件之上,這些條件有的是基於合理的考量,有的則可能不太合適。這裡介紹的「單樣本z檢定」也有三條適用條件:
常態性。一般來說,z檢定必須假定母群分佈符合常態分佈。6這是一個相對合理的條件,若有疑慮,我們有方法可以進行驗證(請參考 小單元 11.9 )。
獨立性。第二條要求構成資料集的觀察值互不相關,或者說,觀察值之間的相關性看不出符合特定模式。這一點不容易直接用統計方法檢驗,而是要依賴嚴謹的實驗設計確保此條件成立。一個明顯違反此條件的不合理例子是,在資料集多次「複製貼上」同一個觀察值,導致得到的資料是基於單一測量結果的巨大“樣本”。實際上,每一個觀察值應該是從目標群體裡完全隨機選出,各別測量而得到的。這項條件在有些研究實務難以完全滿足,但是我們能透過精心安排的研究設計儘可能減少觀察資料之間的相關影響分析結果。
母群標準差已知。z檢定的第三個條件是,研究者必須知道母群的真實標準差。這個條件實在是難以滿足。在現實世界的資料分析中,極少遇到可知母群標準差\(\sigma\),卻對母群平均值\(\mu\)一無所知的情況。也就是說這個條件基本上難以成立。
有鑒於母群標準差已知實在太天方夜譯,我們需要知道除了z檢定的其他統計方法。接著我們要離開z檢定這個看不到生機的沙漠,進入有獨角獸、仙女和小矮人的神奇國度,那就是t檢定!
11.2 單一樣本t檢定
深思熟慮一番後,我們還是無法輕易假定修Zeppo教授課程的心理學系學生成績標準差與其他科系學生的標準差相等。如果我們已經認為不同科系學生的平均成績有差異,為何還要假定他們的標準差相等呢?基於這個理由,我認為不應該預先假定已經知道真正的\(\sigma\)是多少,這麼一來就違反z檢定的適用條件。如此一來,我們的分析工作似乎回到了原點。然而,我們還是有其他方法可用。最重要的是,我們能用一樣的原始資料估計母群標準差,也就是9.52。換言之,雖然我不能假定\(\sigma = 9.5\),但我可以提出\(\hat{\sigma} = 9.52\)。
這是個不錯的開始。你也許會想到,使用樣本估計的標準差9.52來進行z檢定也可以吧,而不用假定\(\sigma = 9.5\),這樣一來依然可以得到顯著的結果。這樣的檢定結果雖然接近正確,但非完全無懈可擊。由於現在是用母群標準差的估計值計算統計值,因此需要調整一下我們對真實母群標準差不確定的想法:或許現在這筆資料僅是一次偶發事件…或許真實的母群標準差其實是\(11\)。如果這是真的,就要假定\(\sigma=11\)來進行z檢定,分析結果就不會顯著了。到底真實的母群標準差是多少,是需要解決的問題。
11.2.1 深入認識單一樣本t檢定
這道史詩級難題在 1908 年被 William Sealy Gosset 解決了。當時他是任職於吉尼斯啤酒公司的化學分析師(參考 Box (1987)),當時的吉尼斯公司禁止員工以個人名義公開發表任何有統計分析的報告,因為公司認為這類報告會透露商業機密,因此Gosset 用了化名“學生”發表他的研究成果。這是為什麼今天t檢定的正式名稱是「學生t檢定」(Student’s t檢定)。Gosset 的關鍵貢獻是,他發現即使我們不完全確定母群標準差的確切數值,如何確保取樣分佈充分匹配真實資料,他提出的解決方法是適當調整取樣分佈7。t檢定的檢定統計值是t統計值(t statistic),如同z檢定的計算方法,我們假定虛無假設的真實平均值是\(\mu\),然而樣本平均值是\(\bar{X}\),根據母群標準差的估計值\(\hat{\sigma}\),t統計值的計算公式是:
\[ t=\frac{\bar{X}-\mu}{\frac{\hat{\sigma}}{\sqrt{N}}} \]
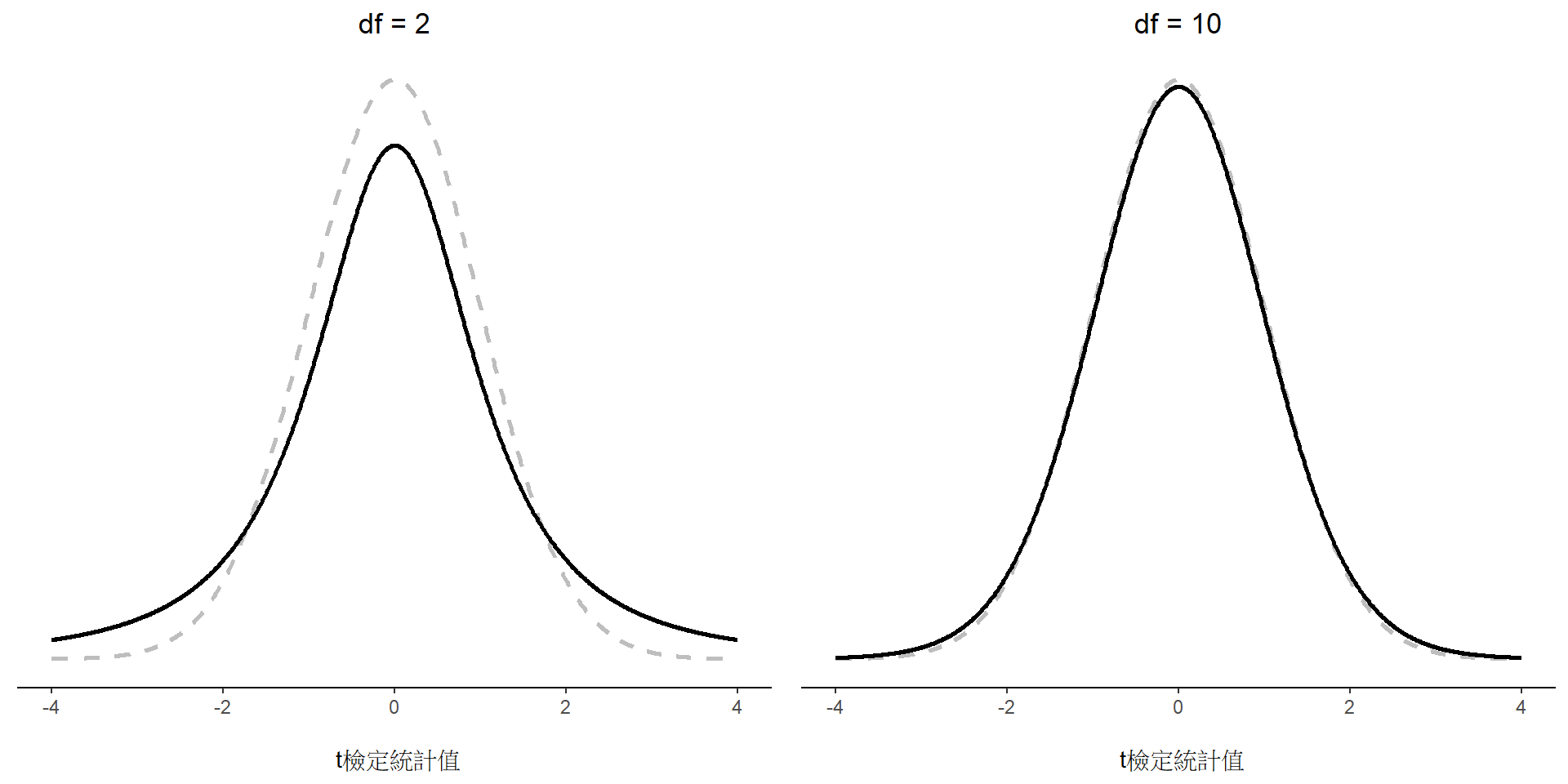
從公式組成來看,t統計值與z統計值的唯一不同是前者 用母群標準差的估計值 \(\hat{\sigma}\) ,代替真實的母群標準差\(\sigma\)。如果這個估計值總和\(n\)個觀察值,這樣的樣本分佈就會符合一個自由度是\(n-1\)的 t 分佈。 t 分佈的長相和常態分佈非常相近,但是兩側尾部的密度稍微高一點。這個特性在 小單元 7.6 曾經提過,也在 圖 11.5 給讀者視覺化解釋。不過,各位讀者應該注意到自由度越大,t 分佈會越來越逼近標準常態分佈,而這就是許多研究者期盼的適用工具,若是樣本量達到\(N = 70,000,000\),母群標準差的「估計值」就幾乎等於真實的母群標準差了?所以如果有大樣本資料可以分析,t 檢定的分析結果幾乎完全等於z檢定,用數學推導來看也是如此!
11.2.2 實作單一樣本t檢定
認真的讀者一定能想通,t檢定的做法和z檢定完全相同。因此,我們沒有必要鑽研繁瑣的計算步驟。兩者要做的計算幾乎一模一樣,只是t檢定是用樣本資料估計的標準差,還有表現統計假設的t分佈而並不是常態分佈。因此,這裡直接展示如何實際進行t檢定。jamovi就有用於執行t檢定的基本分析模組,包含本單元介紹的三種的t檢定。使用方法非常簡單,讀者要做的是從分析模組選單選擇T-Tests -> One-Sample T-Test開啟設定選單,將要分析的資料變項移到到Dependent Variable對話框,接著在Hypothesis-Test Value的對話框裡輸入代表虛無假設的平均值(‘67.5’)。如同 圖 11.6 的展示,除了稍後會提到的統計資訊,置頂表格呈現t檢定統計量=2.25,自由度為19,p值為\(0.036\)。
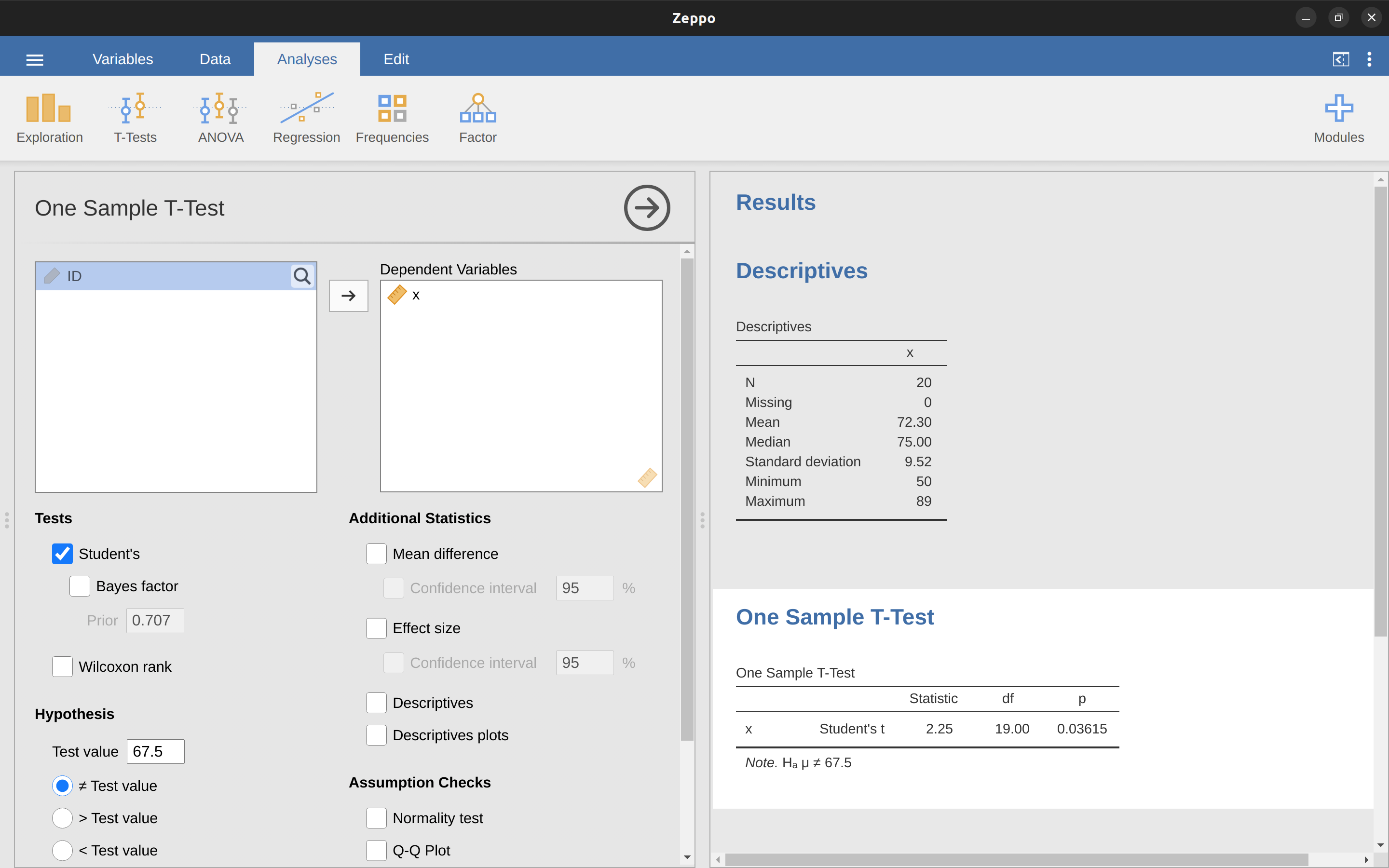
置頂表格包括另外兩個讀者會關係的指標:95%信賴區間和效果量的估計值。那要使用這份表格呢?既然我們是要了解這班心理系學生的學習表現,報告上就能說明他們的成果是真的不錯,因為p值低於0.05,統計檢定顯著的。報告可以這樣撰寫:
心理系學生的平均成績是 \(72.3\),略高於平均成績\(67.5\) (\(t(19) = 2.25\),\(p = .036\))。比平均成績高\(4.80\),\(95\%\)信賴區間為\(0.34\)至\(9.26\)。
以上 \(t(19)\) 是標準的簡寫,代表具有 \(19\) 自由度的 t 統計值。話雖如此,多數報告不會報導信賴區間,或者使用比以上展示的更簡短的形式。像是平均值差異之後信賴區間,通常中括號包圍起來:
\[t(19)=2.25, p = .036, CI_{95} = [0.34, 9.26]\]
在短短幾行裡塞這麼多專業術語,就會讓讀者感到這份報告看起來很厲害。8
11.2.3 單一樣本t檢定的適用條件
那麼單一樣本 t 檢定有什麼適用條件呢?因為 t 檢定基本上就是一個移除了已知標準差假設的 z 檢定,你應該不會意外t檢定具有和z檢定一樣的適用條件,只是少了已知母群標準差這一條:
常態性。我們仍然要假定母群分佈是常態的 9,如同z檢定的適用條件的描述,我們有標準方法可以檢查這種假設是否符合,如果這種假設被違反,還有其他的測試方法可以替代(請參考 小單元 11.9)。
獨立性。同樣地,樣本的觀察值必須是來自彼此獨立的測量條件。詳細說明請參考z檢定的適用條件。
總而言之,這兩個條件並非難以達成,因此單一樣本 t 檢定在實務中常被用於比較樣本平均數與假定的母群平均數有沒有差異。
11.3 獨立樣本t檢定
儘管不乏能用單一樣本 t 檢定解決的統計問題,但這並不是最常用的 t 檢定方法。10通常要處理的統計問題是比較兩組各自測得的資料,許多心理學研究會設計兩個不同測量條件,各自對應一種參與者分組。研究者會以探討的結果變項,請研究參與者做出指定的反應,研究問題就是這兩組參與者反應總計的平均值,是不是來自相同的母群。這種問題就需要使用獨立樣本 t 檢定要解決。
11.3.1 使用獨立樣本t檢定的狀況
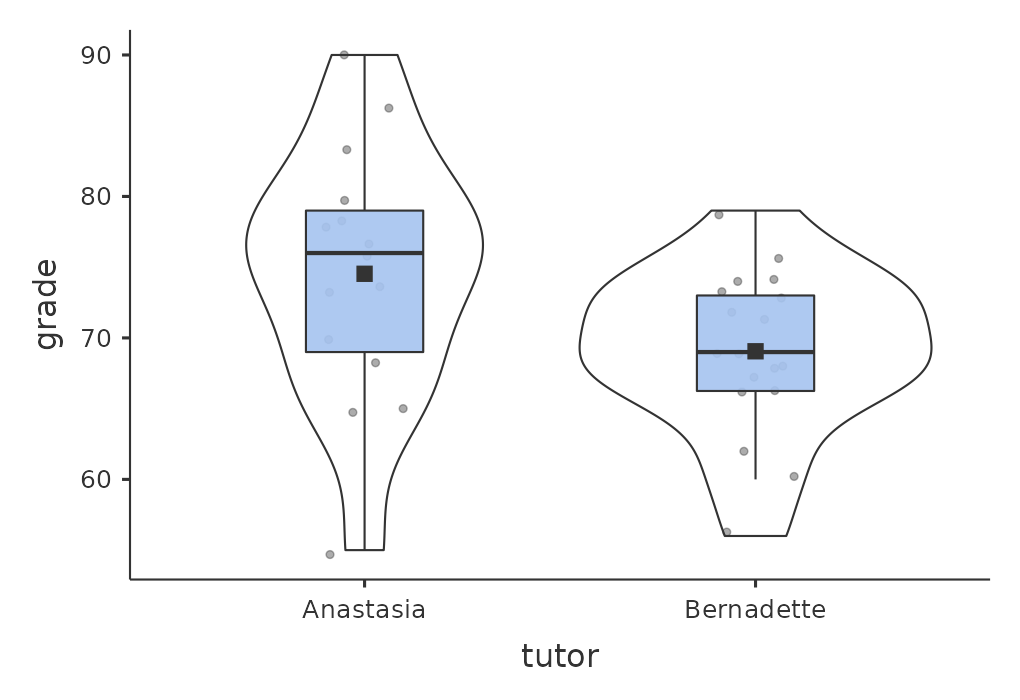
現在想像有一班Harpo老師的統計課程,總共有33 名學生,而Harpo老師給的分數不符合常態分佈曲線。其實,Harpo老師沒透露他的評分方式,他的班上學生平均成績也不得而知。這門課有兩位助教,Anastasia 和 Bernadette,都有開課外加強班。Anastasia 的班 \(N_1=15\) 名學生,Bernadette 則有 \(N_2=18\) 名學生。我想知道的是那位助教的加強班成效較好,還是沒什麼差異。Harpo老師給我的harpo.csv檔案,有所有生的成績。讀者同樣可以由jamovi的資料集裡開啟,這個檔案有三個變項,ID、grade 和 tutor。grade 變項是每個學生的成績,但是剛開始由jamovi預設的測量尺度並不正確,我們要手動更改為連續變項(參考 小單元 3.6)。tutor 變項是一個因子,表示每個學生的助教是 Anastasia 還是 Bernadette。
使用 ‘Exploration’ - ‘descriptives’,可以 分析計算每位助教的學生成績平均值和標準差,得到一個算清楚的摘要表格(表 11.2)。
| mean | std dev | N | |
|---|---|---|---|
| Anastasia's students | 74.53 | 9.00 | 15 |
| Bernadette's students | 69.06 | 5.77 | 18 |
為了讓讀者更清楚知道接下來要做的事, jamovi範例檔案還有箱形圖與小提琴圖,圖中還有代表平均分數的小實心方塊。讓我們更能了解兩位助教的學生成績分佈 (圖 11.7)。
11.3.2 深入認識獨立樣本t檢定
獨立樣本 t 檢定有兩種不同的公式,學生 t 檢定(Student’s t)和Welch’s t 檢定(Welch’s t)。最早出現的學生 t 檢定是比較簡單的一種,而Welch’s t 檢定有更為嚴格的適用條件。像是要進行雙側檢定,要先確定兩個「獨立樣本」是否來自具有相同平均值(虛無假設)或不同平均值(對立假設)的母群。提到「獨立樣本」,真正意思是兩組樣本之間沒有任何關聯性。也許讀者現在可能還不太明白這是什麼意思,到了相依樣本t檢定這一節,就會更清楚。現在想像有一個分成兩組的實驗設計,每位參與者被隨機分派到其中一組,我們想比較這兩組參與者的反應以某種測量尺度紀錄的平均表現,這時我們就需要用獨立樣本 t 檢定,而不是相依樣本 t 檢定。
接著用 \(\mu_1\) 代表 Anastasia 班學生的真實母群平均值, \(\mu_2\) 代表Bernadette 班學生的真實母群平均值11,通常用 \(\bar{X_1}\) 和 \(\bar{X_2}\) 代表兩組的樣本平均值。虛無假設所指的是兩組母群平均值是相同的(\(\mu_1 = \mu_2\)),而對立假設指的是兩組平均值不相同(\(\mu_1 \neq \mu_2\))以數學模型展示的話,就像是 圖 11.8 。
設定能夠處理這項研究問題的假設檢定程虧後,首先可以注意到,如果虛無假設為真,那麼兩個母群平均數之間的差異就是 剛好 為零,\(\mu_1-\mu_2 = 0\)。因此,判斷結果的檢定統計量就是指向兩個樣本平均數之間的差異。若是虛無假設為直,就可以預期 \(\bar{X}_1 - \bar{X}_2\) 非常接近零。然而,就像單一樣本z檢定和單一樣本t檢定的程序,我們必須精確定義兩組平均值差異應該接近零,解決問題的方法和前面兩種檢定幾乎相同。先計算一個標準誤差的估計值(SE),然後將平均值之間的差異除以標準誤差。因此 t 檢定統計量 的公式長成以下的樣子:
\[t=\frac{\bar{X_1}-\bar{X_2}}{SE}\]
接下來的課題是,這個標準誤差估計值是什麼東西。這部分比前面介紹的兩個檢定複雜得多,因此需要一個小節仔細地討論。
11.3.3 標準差的合併估計值
介紹最原始版本的學生 t 檢定時,曾指出適用條件之一是兩組資料有相同的母群標準差。換句話說,無論母群平均數是否相同,母群標準差都要是相同的,\(\sigma_1 = \sigma_2\)。因為設定兩組母群標準差相同,在此省略符號的下標,統一用 \(\sigma\) 代表。那麼我們該如何估計這個值?當我們有兩組樣本時,該如何計算的單一標準差估計值?答案有點簡單,只要將它們加起來平均。實際上,我們會取一個加權平均的變異數估計值,做為合併變異數的估計值。分配給每個樣本的權重等於該樣本的觀察值個數減去 1。
[其他技術細節12]
11.4 獨立樣本t檢定的更多細節
無論讀者想以那種方式理解,我們現在有了樣本標準差的合併估計值。現在開始使用的符號,不會再加上那個奇怪的下標\(_p\),只寫成\(\hat{\sigma}\)。好極了,現在回來繼續說明這個該死的假設檢定程序吧?我們計算標準誤的合併估計值的主要原因是因為這種方法非常有用,但是標準誤究竟是什麼? 單一樣本t檢定的樣本平均值標準誤是\(se(\bar{X})\),因為\(se(\bar{X}) = \frac{\sigma}{\sqrt{N}}\),也就是t統計值的分母。然而,在獨立樣本的設計,我們有兩個樣本平均值。而研究者真正有興趣的是兩組之間的差異\(\bar{X}_1-\bar{X}_2\),因此,放在分母的標準誤,真面目是平均值差異的標準誤。
[其他技術細節13]
如同單一樣本t檢定所學到的,只要虛無假設為真,而且都符合所有適要條件,t 統計值的取樣分佈就是 t 分佈。然而,這裡的自由度計算方法略有不同。通常,我們可以把自由度視為資料點個數減去要估計的變項個數。有關獨立組設計,我們有 \(n\) 個觀察值(樣本 1有\(n_1\) 個,樣本 2 有\(n_2\)個),和 2 個變項(樣本平均值)。因此,獨立樣本t檢定的自由度是 \(n_1 + n_2 -2\)。
11.4.1 jamovi實作
讀者應該很容易猜到,jamovi一定可以處理獨立樣本 t 檢定。這裡的依變項是學生成績,各組助教是由主課老師指派的。所以,讀者應該知道要怎麼從模組選單呼叫獨立樣本 t 檢定(T-Tests -> Independent Samples Tests),如 圖 11.9 的展示,將資料變項grade移動到Dependent Variables對話框,將資料變項tutor移動到Grouping Variable對話框。
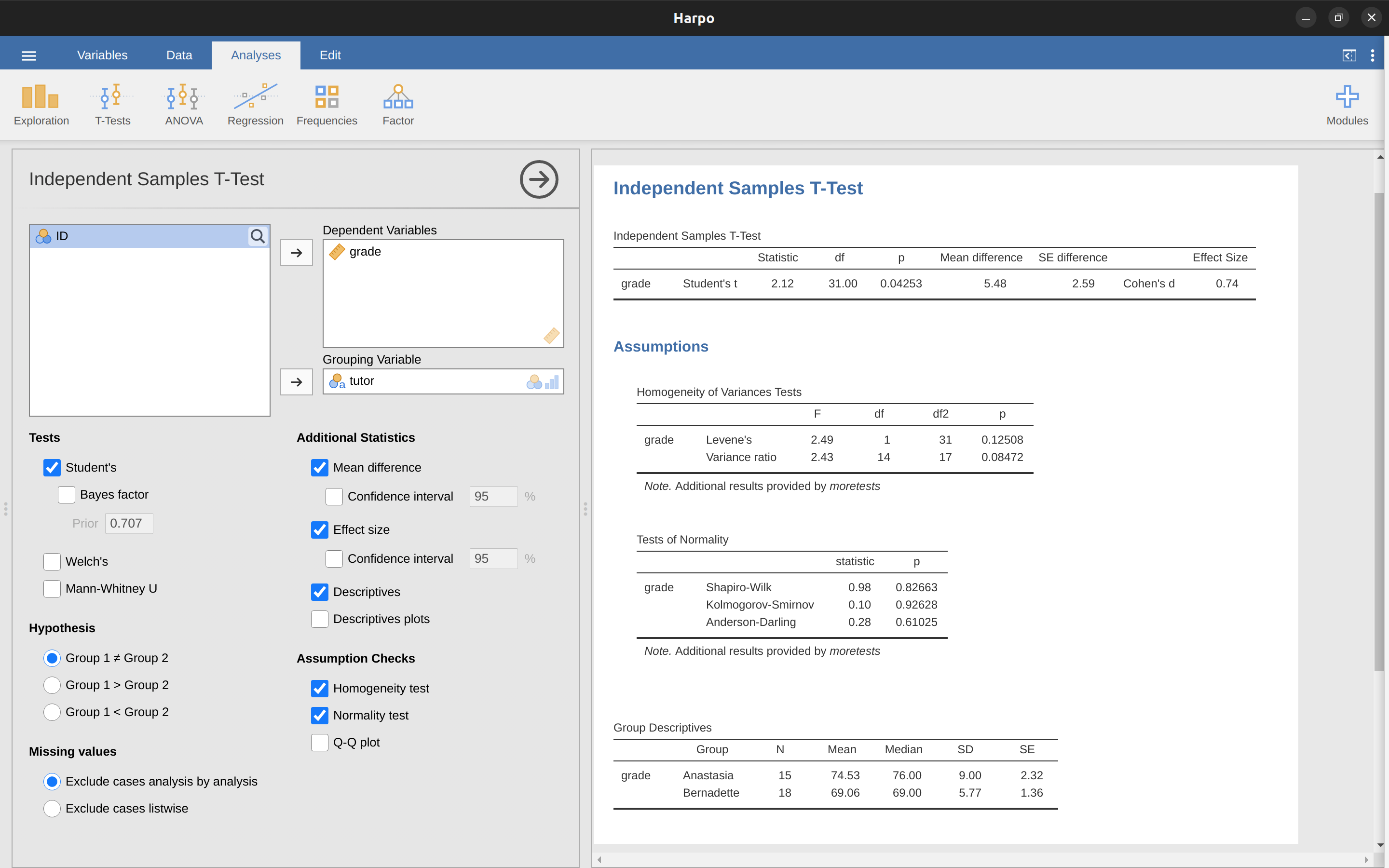
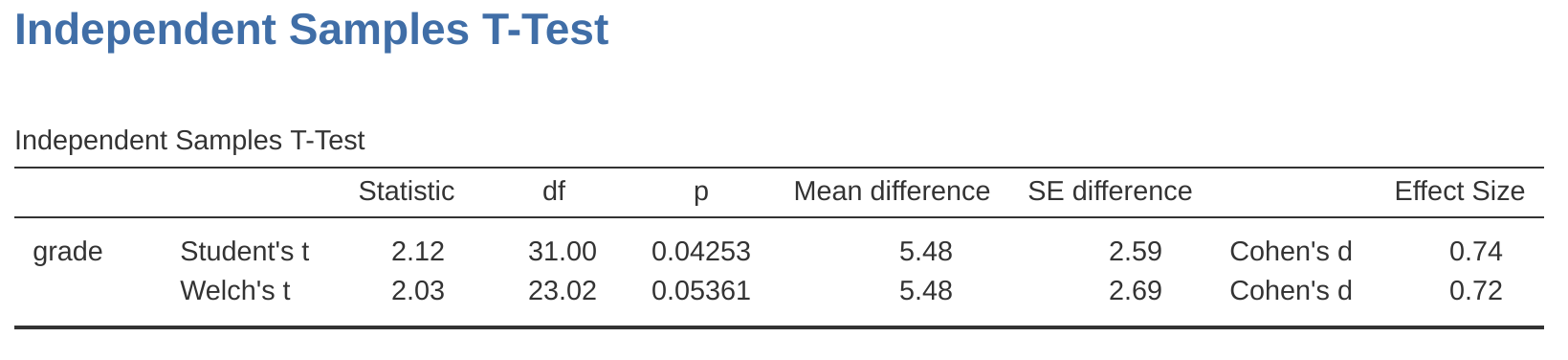
各位應該熟悉報表的輸出格式了。標題提示檢定方法,置頂表格印出依變項名稱,以及分組依變項差異的檢定結果。檢定結果包括 t 統計值、自由度和 p 值。還有效果量(Effect Size)及其信賴區間。我們先討論信賴區間,稍後再談一談效果量。
讀者可以先回顧一下 小單元 8.5 ,重溫信賴區間的意思,這裡的信賴區間則是指兩組平均數差異的信賴區間。這個範例的Anastasia組的平均成績為74.53,Bernadette組平均成績為69.06,因此兩組平均數差異值是5.48。但是,兩個母群的平均數差異可能比這個差異值更大或者更小。 圖 11.9 14呈現的信賴區間告訴我們,如果重複進行這個研究,那麼有95%的結果,會落在0.20和10.76之間。
就報表資訊來看,兩組之間的差異是剛剛好顯著。因此,我們可以在報告裡這樣撰寫:
Anastasia 組的學生平均成績為 \(74.5\)(標準差為 \(9.0\)),而 Bernadette 組的學生平均成績為 \(69.1\)(標準差為 \(5.8\))。 獨立樣本 t 檢定顯示兩組成績的差異 \(5.4\) 是顯著的 \((t(31) = 2.1, p<.05, CI_{95} = [0.2, 10.8], d = .74)\),顯示分組的學習成效有明顯差異。
請留意以上報告範例有信賴區間和效果量,不過很少有報告這樣寫。最多會看到t統計值、自由度和p值。所以讀者自已的報告至少要這樣寫:\(t(31) = 2.1, p< .05\)。統計學專家會期待每份統計結果報告,都會有信賴區間,還有效果量的測量,因為這些都是有用的資訊。但是現實世界並不會完全按照統計學家的期望運作,正在寫論文的同學應該根據能夠幫助讀者的原則來決定報告要什麼,要投稿期刊的話,就應該遵照期刊編輯公告的標準。有些期刊會希望作者報告效果量,有些則不用。某些科學社群的標準格式是要報告信賴區間,有些則不是,這需要由作者自已找出目標讀者的需要。如果為了幫助讀者清楚理解,以原作者在課堂上常給的建議,信賴區間和效果量是值得寫出來的。
11.4.2 t統計值正負的意義
繼續談t檢定的適用條件之前,我們先來討論t檢定的實務還有一個重要觀點。首先是關於t統計值的前面,究竟要不要加上負號( - )。許多學生第一次演練t檢定時,常常會擔心算出負值,就不知道怎麼解釋。其實現實的研究案例經常會看到,一項實驗由兩位不同的人各自獨立進行,獲得的結果幾乎相同,但是其中一位算出的t值是負的,另一位的t值是正的。若進行的是雙側檢定,那麼p值會是相同的。再仔細檢查一次後,學生們通常會發現信賴區間也是相反的,這是完全正常的。每當這類情況發生時,你會發現兩種不同的結果是由稍微不同的t檢定方法引起的。這裡發生的事情非常簡單,這個單元學到的t統計值都是具備以下的形式
\[t=\frac{\text{平均值1-平均值2}}{SE}\]
如果 “平均值 1” 大於 “平均值 2”,則 t 統計值就會是正數,而如果 “平均值 2” 大於 “平均值 1”,則 t 統計值就會是負數。同樣地,jamovi 報告的信賴區間是 “(平均值 1) 減去 (平均值 2)” 差異的信賴區間,與 “(平均值 2) 減去 (平均值 1)” 差異信賴區間剛好相反。
好啦,想通這一點後,會覺得很簡單,但現在要來算一算比較Anastasia和Bernadette兩位助教輔導成效的 t 檢定了。我們應該把哪一個命名為 “平均值 1”,哪一個命名為 “平均值 2”,其實你可以任意決定。然而,實作中真的需要將其中之一指定為 “平均值1”,另一個為 “平均值 2”。毫不意外,jamovi 介面的處理提示也相當任意。在本書早期的版本,原作者曾試著花些功夫解釋,但經過幾次改版後,現在已經放棄了,因為如何命名並不是真正重要的事情,老實說原作者自己也記不清楚為何一開始要試著解釋。有經驗的研究者看到一個顯著的 t 檢定結果,想知道那一組的平均值較大,其實不會去看t 統計值是多少,而是直接看分組平均值。為什麼不必看t統計值,因為 jamovi 輸出的表格就一目了解地印出分組平均值!
這是重要的一點。因為 jamovi 輸出的報表其實不是完全符合報告規範的,通常報告中出現的報告 t 統計值要重新編輯。如果我想在報告中寫道:「阿納斯塔西亞輔導的學生成績高於Bernadette的學生。」這種措辭意味著阿納斯塔西亞的班排在前面,因此把阿納斯塔西亞設定為第一組是有道理的。若是如此,我會寫成 阿納斯塔西亞輔導的學生成續比Bernadette輔導的學生更高\((t(31) = 2.1,p = .04)\)。
真正的報告寫作不會真的用底線來強調 ,這樣寫只是為了強調 高 對應 t 統計值的正數。另一方面,若是想要強調 Bernadette 的輔導成效,把她的班級指定為第一組更有意義,這樣的話報告應該寫成:Bernadette 輔導的學生成績比 Anastasia 的學生低 \((t(31) = -2.1, p = .04)\)。
最後要注意的是,這種報告的寫作格式只適用t檢定,對於卡方檢定、F檢定、或本書提到的大多數檢定方法並無意義。因此不要將這個建議過度類比使用!在這裡真的只有談論t檢定,而不是其他統計方法!
11.4.3 獨立樣本t檢定的適用條件
和單一樣本t檢定一樣,學生t檢定也有三項適用條件 ,其中一些在單一樣本t檢定的適用條件已經提到:
- 常態性。和單一樣本t檢定一樣,樣本資料的取樣分佈必須是符合常態分佈。具體來說,兩組樣本資料都需要符合常態分佈。15在[檢查樣本常態性]一節,我們將討論如何檢查常態性;在@sec-Checking-the-normality-of-a-sample一節,我們將討論可能的解決方案。
- 獨立性。其次是要確保每個資料觀測值的取樣是獨立的。以能運算學生t檢定的條件來說,有兩個性質需要考慮。首先,和單一樣本t檢定一樣,需要設定每個樣本包含的觀測值是相互獨立的。此外,我們還需要設定兩個樣本之間沒有相互依賴關係。例如,如果實驗中同一個人被不小心分派參與兩種條件組,像是同一個人不小心被允許報名參加不同條件的兩項獨立實驗,這麼一來就會造成一些跨樣本的依賴關係。
- 變異數的同質性(又稱“等變異性”)。第三個條件 是指兩組的母群標準差必須是相等的,我們可以使用Levene檢定來測試這個假設,稍後在[檢查同質變異性的假設]示範。然而,如果您擔心違反這個條件,有一個非常簡單的解決方法,我們將在下一節中討論。
11.5 獨立樣本t檢定(Welch’s t檢定)
使用學生 t 檢定處理真正的統計問題,最大挑戰是變異數同 性的條件很難符合。現實的研究問題,很少存在變異數相等的兩組樣本資料。如果兩組樣本的平均值並不相等,有什麼理由期待兩組樣本的標準差相等呢?實際上許多研究者也不會計較資料有沒有符合變異數同質性。稍後會介紹如何檢查變異數同質性,因為許多統計方法都要依賴這個條件。此節先帶讀者們認識不需要依賴變異數同質性的 t 檢定~ Welch’s t檢定 (Welch, 1947)。 圖 11.10 展示變異數不相等的統計假設,讀者可對比 圖 11.8 ,適用學生t檢定的統計假設。在說明如何診斷是否適用之前,介紹如何實作修正方法是有點奇怪,但是 Welch’s t 檢定可以在 jamovi 的「獨立樣本 t 檢定」模組選單中直接勾選,所以以下先介紹如何實作。
Welch’s t 檢定與 Student t 檢定的公式非常相似。計算 t 統計值的大同小異,都是取樣本平均數之間的差異,然後除以其標準誤的估計:
\[t=\frac{\bar{X}_1-\bar{X}_2}{SE(\bar{X}_1-\bar{X}_2)}\]
兩者的差異是標準誤的計算方式。若是兩組取樣的標準差並不相等,計算合併的標準差估計值是沒有意義的,這麼做就像是要把蘋果和橘子攪在一起。16
[其他技術細節 17]
Welch’s t 與 Student t 的第二個差異是自由度的計算方式。 Welch’s t的自由度不必是一個整數,並且不太符合「資料點數量減去約束數量」的解釋方式,雖然這是原作者(還有世界上多數教統計的老師)到目前為止一直採納的解釋。
11.5.1 jamovi實作
只要在 圖 11.9 的設定選單裡勾選 Welch’s ,就會得到 圖 11.11 。
輸出結果應該不用多做解釋,讀者可以像解讀學生t檢定的結果一樣,解讀Welch’s t 檢定的結果。加上描述統計資料,測試結果和其他訊息,就能做出有模有樣的報告。
只是我們要注意,就是這裡的Welch’s t檢定結果是不顯著的。報表顯示學生t檢定分析這個組間差異是顯著的,但是Welch’s t檢定顯示未達顯著 \((t(23.02) = 2.03, p = .054)\)。 這是什麼意思?我們要放棄嗎?可能不用。
一個檢定顯著,但是另一個檢定不顯著其實並沒有什麼意義,特別是這些資料是是編造出來的。通常不必去解釋\(.049\)和\(.051\)這兩個p值有何不同,如果有現實的資料分析發現這樣的事,可以肯定完全是偶然性的結果。做分析的人要思考的是:我選擇使用那一種檢定方法的理由是什麼?學生t和Welch’s t各有優缺點。當兩組樣本的變異相等,學生t檢定的統計考驗力比Welch’s t檢定更高,或者說型II錯誤率較低。當兩組樣本的變異不相等,學生t檢定就會違反適用條件,導致型I錯誤率增加。所以要選那一種,需要使用者權衡。現實的心理學研究,有越來越多研究者喜歡使用Welch’s t檢定,因為幾乎沒有研究問題的分組樣本變異數是相等的。
11.5.2 Welch’s t檢定的適用條件
Welch’s t檢定的適用條件與學生t檢定幾乎一樣,只是Welch’s t檢定不需要符合變異數同質性。只要符合常態性和獨立性,細節請參考單一樣本t檢定的適用條件。
11.6 相依樣本t檢定
不論是學生 t 檢定或Welch’s t 檢定,獨立樣本 t 檢定只能處理兩組獨立樣本的研究資料。當參與者被隨機分派到其中一個實驗條件時,自然會符合獨立樣本的條件,但是很難處理其他類型的研究設計。特別是重覆測量的研究設計,並不適合使用獨立樣本 t 檢定進行分析。例如,有研究者想探討聽音樂是否降低人們的工作記憶容量,讓每位參與者分別在有音樂和無音樂的情況,測量他們的工作記憶容量。這樣的設計讓每位參與者接受兩種實驗條件18,因此我們需要認識相依樣本t檢定。
11.6.1 示範資料
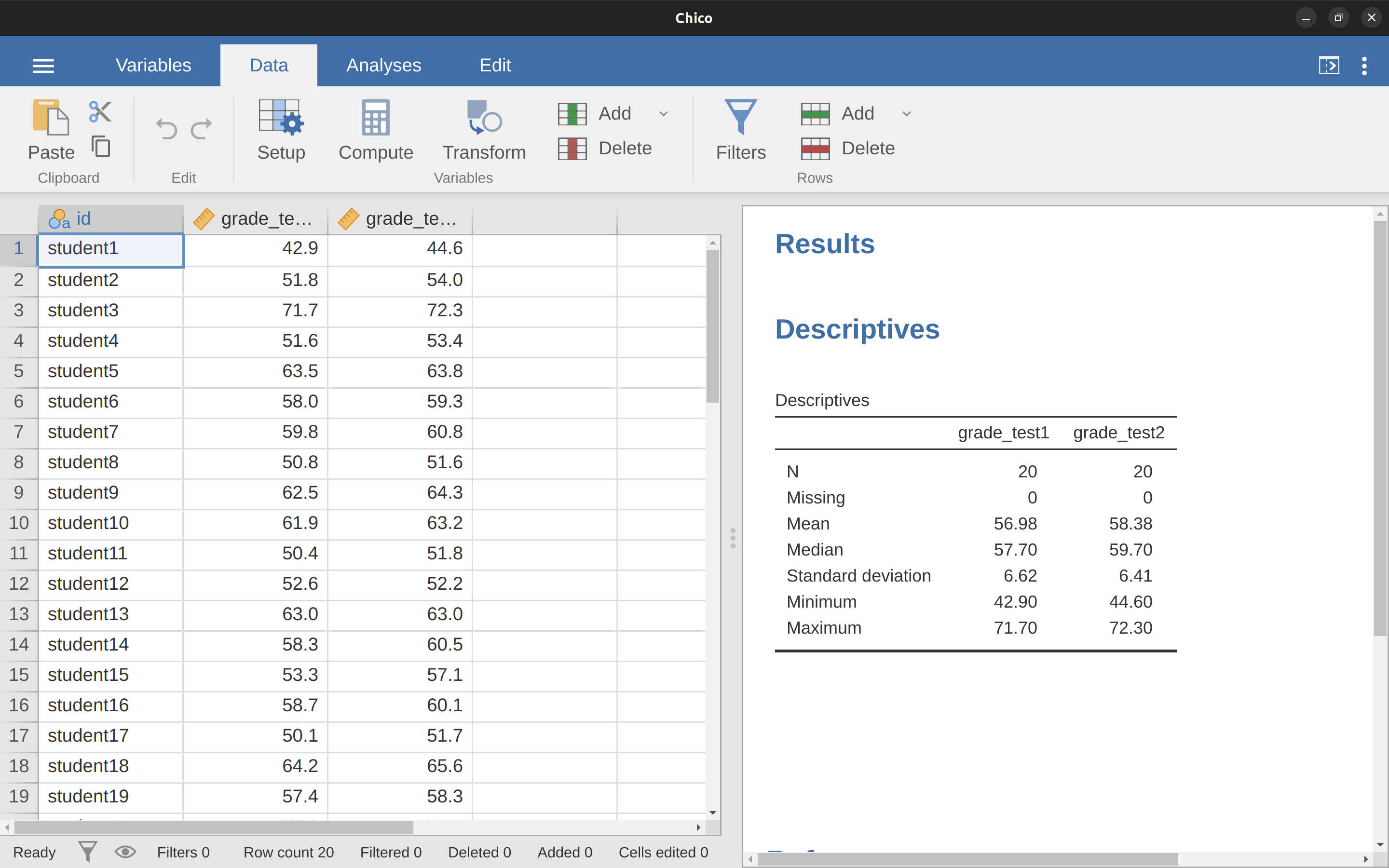
這次要分析的是修Chico老師課程的學生成績。19她的學生都要參加學期初和學期末兩次大考,而且考試內容很難,大多數學生都覺得很有挑戰性。Chico老師的想法是,增加考試難度能激勵學生的學習動機。她的理論是,第一次考試對學生來說是一個“提醒”,當他們意識到課程的難度,會為了第二次考試取得更好的成績,而更加努力。Chico老師的觀點正確嗎?請讀者開啟jamovi資料集裡的範例檔chico。這次資料匯入jamovi後,每個變項的測量尺度都是正確的。chico資料集有三個變項:id ~ 每位學生的識別代號,grade_test1 ~ 第一次考試的學生成績,grade_test2 ~ 第二次考試的成績。
瞄一下展示在 圖 11.12 的 jamovi 資料試算表,這門課程似乎滿有難度,多數學生的成績都在50分到60分之間,不過第一次測驗到第二次測驗看起來有進步的趨勢。
再來瞄一下描述統計表,前一段提到的印象似乎有些道理。全班20位學生的第一次測驗平均成績是57分,第二次測驗的平均成績是58分。因為兩次測驗的標準差分別為6.6和6.4,這種進步感覺起來只是表面的,可能只是隨機出現的結果。繼續看到 圖 11.13 (a) 展示的平均值和信賴區間後,很多讀者會更相信這班學生沒有步。因為只看信賴區間的寬度,我們會認為學生學習成果的改善只是偶然的。
不過,直覺的印象其實是錯的。要知道為什麼,請看 圖 11.13 (b) 展示的第一次和第二次成績的散佈圖。圖中的每個點對應一位學生的兩次成績。如果他們的第一次成績(x軸)等於第二次成績(y軸),每個點應該都會落在直線上,落在線上方的點是第二次測試成績有進步的學生。重要的是,幾乎所有資料點都在對角線以上,表示幾乎所有學生成績都有提高一些,即使只有一點點。這顯示原始資料應該是每個學生的第一次測驗到第二次測驗的進步幅度,因此我們需要在chico 資料集裡建立一個新變項,表示每位學生的進步分數。最簡單的方法是建立一個計算變項,函式欄位裡就置入 grade test2 - grade test1。
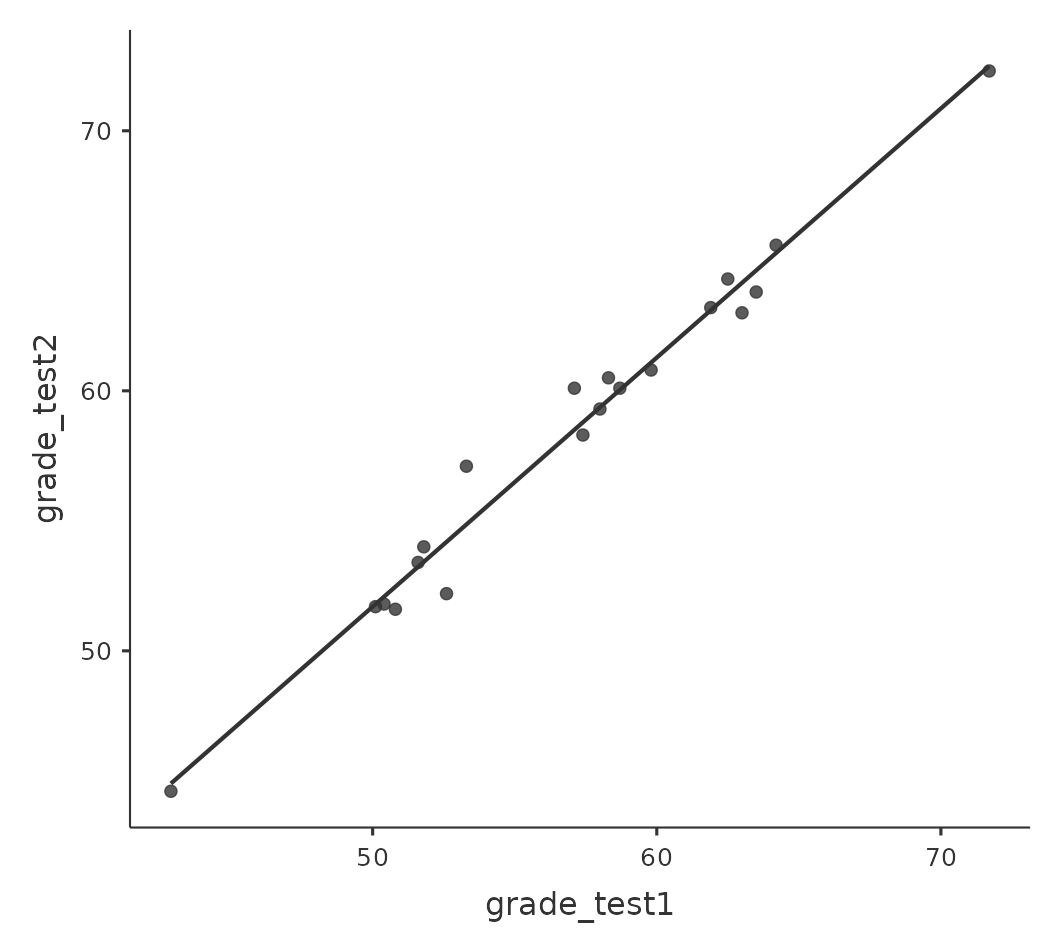
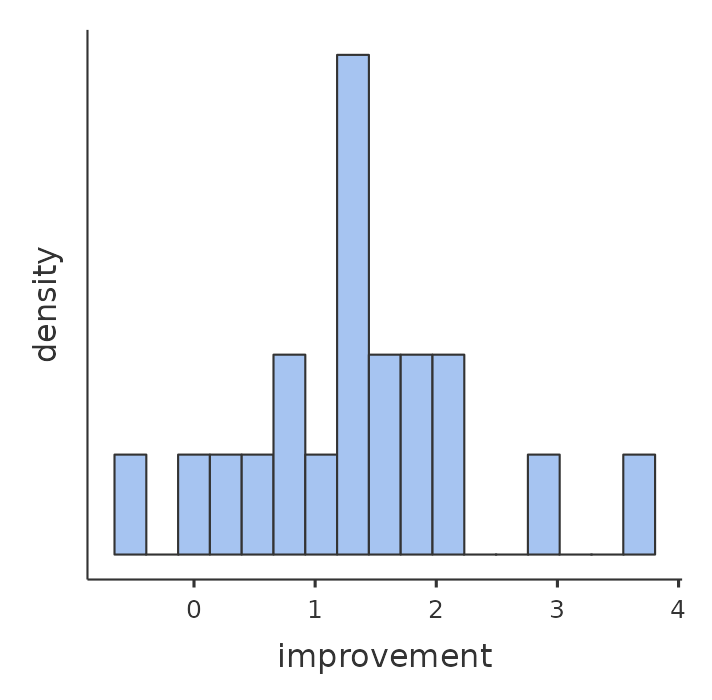
用新建立的變項畫出直方圖,就能顯示全班學生進步分數的分佈,如同 圖 11.14 的輸出結果。仔細看一下這個直方圖,能明顯看到每位學生真的有進步。因為整張圖的大部分數值條分佈在大於零的區域,反映絕大多數學生的第二次測驗得分比第一次高。
11.6.2 深入認識相依樣本t檢定
延續前面的討論,接著來思考如何建立一個合適的 t 檢定程序。目前所知的可行方法是採用獨立樣本 t 檢定,比較grade_test1和grade_test2在結果變項的差異。不過,使用獨立樣本 t 檢定顯然是錯誤的,因為必須設定兩組樣本之間沒有特定關聯性。由於樣本資料是重複測量形成的,很顯然有存在關聯性。以 單元 2 提過的影響研究效度的各種設計條件來說,使用獨立樣本 t 檢定的話,會混淆這裡要檢定的 樣本內 差異及非檢定目標的樣本間 變異。
因為在 小單元 11.3 ,讀者應該已經搞清楚最難懂的部分,要解決這個問題的方法很明確。這裡不是將grade_test1和grade_test2分組進行獨立樣本t檢定,而是對集合進步分數的差異變項improvement進行相依樣本t檢定。改用數學符號描述的話,\(X_{i1}\)是第i個參與者在grade_test1的分數,\(X_{i2}\)是同一個人在grade_test2的分數,所以差異分數是:
\[D_i=X_{i1}-X_{i2}\]
請注意,差異分數是變項1減變項2的數值,而不是反過來。若是要有採用多數為正數的差異分數,實務要將grade_test2當做「變項1」。同樣地,我們會定義 \(\mu_D = \mu_1 - \mu_2\) 是差異分數的母群平均值。運用這套符號設定統計假設,虛無假設會表示此差異值是零,對立假設則表示不是零:
\[H_0:\mu_D=0\] \[H_1:\mu_D \neq 0\]
這裡設定鎮進行雙側檢定,進行與前面介紹的t檢定程序一樣的假設檢定。唯一不同之處是虛無假設所設定的期望值為0。所以,t 統計值可以用類似的定義方式。如果用 \(\bar{D}\) 代表差異分數的平均值,t統計值就是
\[t=\frac{\bar{D}}{SE(\bar{D})}\]
分母的 \(\hat{\sigma}_D\) 是差異得分的標準差。因為這與單一樣本 t 檢定的內容沒有什麼不同之處,所以自由度仍然是 \(n - 1\),至此我們該知道的都說完了。其實相依樣本 t 檢定並不是另一種的新方法,這種方法的本質就是檢測兩個變項之間差異分數的單一樣本 t 檢定,執行程序設定其實非常簡單。我們需要花這麼多篇幅討論的唯一原因是,使用本書學習的讀者要有能力辨認何時適用相依樣本t檢定,還有為什麼這個情況比獨立樣本 t 檢定更適合。
11.6.3 jamovi實作
如何使用jamovi執行相依樣本t檢定?其中一種方法是按照上面示範說明,執行單一樣本t檢定。實作方法是創建一個新的資料變項,以此執行單一樣本t檢定。因為按照上面的說明,讀者應該已經創建improvement計算變項,我們就順著步驟做下去,看看能不能得到 圖 11.15 的檢定結果。

圖 11.15 的報表與 小單元 11.2 示範的單一樣本t檢定報表格式完全相同,確認我們對這筆資料的觀察無誤。第二次測驗比第一次測驗相比,平均增加了1.4分,並且與沒有改進的0顯著不同\((t(19)=6.48,p<.001)\)。
假如讀者想偷懶,不想再造一個新資料變項,或是清楚區別單一樣本t檢定和相依樣本t檢定的差異。那麼,我們可以使用jamovi的Paried Samples T-Test,獲得 圖 11.16 顯示的結果。

兩種檢定結果完全相同,這是因為成對樣本t檢定的本質,就是對差異變項執行單一樣本t檢定。
11.7 單側檢定
小單元 9.4.3 首次介紹虛無假設檢定理論時,曾提到有一些情況適合執行單側檢定。至此介紹的t檢定,所有示範都是雙側檢定。例如,用單一樣本t檢定分析Zeppo老師的學生成績,虛無假設平均值是\(67.5\);對立假設是理論平均值高於或低於\(67.5\)。如果我們只想知道理論平均值是否高於\(67.5\),並不想測試理論平均值是不是低於\(67.5\%\)。如此一來,虛無假設就要改成理論平均值為\(67.5\%\)或更低,對立假設要改成理論平均值高於\(67.5\%\)。用jamovi執行這樣的檢定,只要在設定選單的Hypothesis,勾選> Test value,就能得到 圖 11.17 的結果輸出。
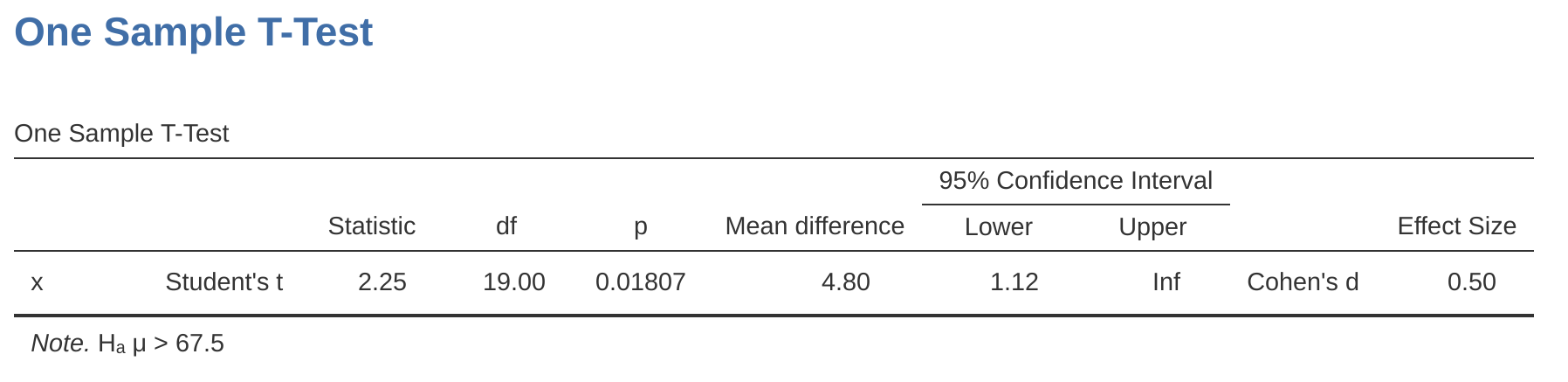
各位可以看到表格內容和 圖 11.6 不同一樣,最重要的是表格附註有關對立假設的描述,表示我們想測試的假設。其次要注意的是儘管t統計值和自由度沒有改變,但是p值已經不一樣了。這是因為單側檢定的拒絕區域不同於雙側檢定。如果讀者忘了拒絕區域是什麼意思,請重溫 單元 9 ,特別是 小單元 9.4.3 。還有要注意的是信賴區間也不一樣:新報表輸出的是“單側”的信賴區間,而不是雙側的信賴區間。雙側信賴區間會有兩個數字a和b,代表重複進行這項研究多次,會有\(95\%\)的機會,平均值會落在a和b之間。單側信賴區間只會有一個數字a,代表重複進行這項研究多次,會有\(95\%\)的機會,平均值會大於a。反之,如果Hypothesis選了Test 1 < Test 2,就會得到小於a的信賴區間。
各種t檢定都能進行單側檢定。以獨立樣本t檢定來說,如果只想測試A組的得分有沒有比B組高,但對於沒有興趣知道B組的得分是不是高於A組,就適合進行單側檢定。以Harpo老師的案例來說,我們想了解Anastasia組的學生是否比Bernadette組的學生成績好。只要在設定選單的Hypothesis勾選Group 1 > Group2,就能得到如 圖 11.18 的結果。
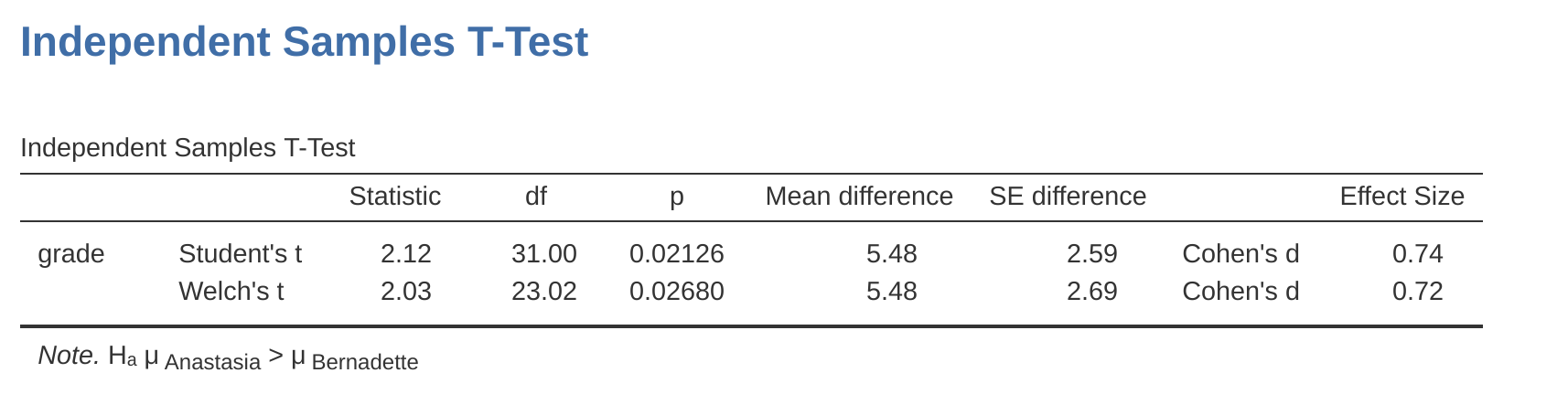
這裡再次提醒,報表輸出內容和雙側檢定不一樣的地方。對立假設的定義、p值都不一樣,信賴區間只有一個數字了。
那相依樣本t檢定會怎麼樣呢?也就是想知道Zeppo老師學生的第二次考試有沒有比第一次考試高,不考慮分數下滑的機會。只要在jamovi的設定選單,指定”grade_test2”為Measure 1,並勾選Hypothesis的Measure 1 > Measure 2,就能看到 圖 11.19 的結果。

這次的輸出改變的部分和前面一樣,附註的假設,p值都會改變,並且信賴區間只有單側的數值。
11.8 t檢定的效果量
最常搭配t檢定的效果量指標是Cohen’s d (Cohen, 1988)。Cohen’s d的原理看似簡單,不過仔細研究的話,會看到各式各樣的版本。原始發明者提出的版本是為了定義充分符合適用條件的獨立樣本t檢定的效果量,也就是學生t。這個版本定義的效果量測量方法,自然是估計兩組平均值差異除以標準差。正如以下公式的簡明版描述:
\[d=\frac{(\text{平均值1})-(\text{平均值2})}{\text{標準差}}\]
原始發明者建議的Cohen’s d簡易使用指南列在 表 11.3 。
| d-value | rough interpretation |
|---|---|
| about 0.2 | "small" effect |
| about 0.5 | "moderate" effect |
| about 0.8 | "large" effect |
也許有讀者覺得這份指南很有幫助,實際上並非如此。因為科恩並未提供太多以標準差做為測量單位的實用建議,他的著作其實是想要是闡述一個更廣泛的觀點。就像 McGrath & Meyer (2006) 提到的幾種版本,每個學者各有偏好的參考指南。本書採用不大精確的簡化符號,從這裡開始所提到的\(d\)代表由樣本資料計算的效果量估計值,\(\delta\)表示理論的效果量。讀者要學習如何分辨符號的使用脈絡。
本書提到的所有統計方法都有可以運算的效果量,需要計算Cohen’s d只有t檢定,jamovi的每個t檢定模組都有一個選項,讓使用者決定要不要在報表輸出Cohen’s d。
11.8.1 單一樣本的Cohen’s d
單一樣本t檢定的Cohen’s d是最單純的,效果量表示樣本平均值\(\bar{X}\)和母群平均值\(\mu_0\)的差異,並且有估計群體標準差\(\hat{\sigma}\)的合理方法,因此計算\(d\)的公式只有
\[d=\frac{\bar{X}-\mu_0}{\hat{\sigma}}\]
回顧 圖 11.6 的分析報表,效果量是Cohen’s d = 0.50。所以說,如果Zeppo老師的大部分學生成績接近預期水準(67.5),班上心理系學生成績(mean = 72.3)比預期水準高約0.5個標準差。根據 表 11.3 ,這是一個中等效果量。
11.8.2 獨立樣本的Cohen’s d
許多介紹Cohen’s d的教材只有談到獨立樣本t檢定,各種教材使用的符號分歧,加上分母成分的選擇不只一種,造成許多學生不知該學那一套,加上每位統計教師為了解釋如何處理獨立樣本問題,產生多種計算\(d\)的公式。為了統整各家公式,建議讀者先多看看,也可以手寫一下代表理論母群效果量\(\delta\)的公式來加深印象:
\[\delta=\frac{\mu_1-\mu_2}{\sigma}\]
如同 單元 8 提到的符號說明,\(\mu_1\)和\(\mu_2\)分別是指第1組與第2組的母群平均值,\(\sigma\)代表母群標準差,如果兩組都是來自同一個母群的話。所以\(\delta\)的估計值與t統計數的公式幾乎一致,也就是分子是樣本平均值,分母是合併的標準差估計值
\[d=\frac{\bar{X}_1-\bar{X}_2}{\hat{\sigma}_p}\]
\(\hat{\sigma}_p\)的估計值就是獨立樣本t檢定的標準差的合併估計值這一節所介紹的公式,這是搭配Student t檢定所使用的Cohen’s d,也是jamovi報表的輸出結果。有時也被稱為Hedges’ g (Hedges, 1981)。
除此之外還有其他計算方法,這裡簡單介紹一下。若是只想用其中一組的樣本標準差做為計算基礎,也就是研究者有充分理由認定其中一組比另一組能更純粹地反映「自然變異」,就可以使用Glass’ \(\triangle\)。像是其中一組是對照組時,有統計學者使用Glass’ \(\triangle\)才是\(\delta\)的合理估計值。再者 ,獨立樣本的合併標準差計算公式裡,分母通常是\(n - 2\)以校正估計值。另一個Cohen’s d的版本則沒有這樣的校正,分母就是\(n\)。這個版本適用於研究者只想計算以樣本為主的效果量,而非估計\(\delta\)。最後,還有 Hedges & Olkin (1985) 提出的Hedges’ g也是不少研究者會採用的計算方法,這個方法是對Cohen’s d的合併標準差做更進一步的校正。20
11.8.3 相依樣本的Cohen’s d
最後是相依樣本t檢定,要怎麼計算呢?這要取決於研究者的目標。jamovi的預設是根據差異分數的分佈來衡量效果量,計算公式是:
\[d=\frac{\bar{D}}{\hat{\sigma}_D}\]
分母的\(\hat{\sigma}_D\)是差異的標準差估計。 圖 11.16 報表裡的Cohen’s \(d = 1.45\),表示第2次測驗的分數平均比第1次測驗的分數高\(1.45\)個標準差。
這就是jamovi「相依樣本t檢定」分析報告的Cohen’s d的計算方法,寫正式報告前唯一的麻煩是要搞清楚這是不是真正的估計值。這要看研究者是想用原始分數,還是用差異分數衡量效果量,像是以Chico老師教的學生成績變異值來看,兩次測驗只有改進1%看起來不大明顯。這個狀況很像要選擇用Student’s t 檢定還是Welch’s t檢定 評估兩組之間的差異。想要以原始分數計算Cohen’s d,就要從資料試算表更改資料結構,雖 在這裡不方便說明及示範21,我們可以算出\(0.22\),以原始分數來說是偏小的效果量。
11.9 檢測樣本常態性
這個單元介紹所有檢定方法都需要的適用條件~樣本資料要符合常態性,根據中心極限定理(見 小單元 8.3.3 ),來自隨機取樣的樣本只要數量夠大,樣本分佈都會符合常態分佈,所以這個條件通常是合理的。研究者通常關心的變項實際上是由多項觀察的平均值構成樣本,累積的樣本很可能符合常態分佈,或者至少接近常態分佈,讓研究者能安心使用t檢定。但是現實世界不會給研究者保證,有許多偏差的研究方法會造成變項的樣本形成非常態的分佈。像是樣本資料都是研究變項尺度的最小值,可能造成偏斜的分佈。許多心理學實驗會測量的反應時間就是一個很好的例子。如果研究者認為許多條件都會觸發人類參與者的反應,最真實的反應只會出現在研究者感興趣的觸發事件第一次發生之後。22如此,將導致反應時間資料分佈不符合常態性。那麼,如果常態性是所有檢定方法必須符合的條件,現實世界的多數樣本資料也能符合,那麼要如何檢查樣本的常態性呢?以下介紹兩種方法:分位數對分位數圖(Q-Q plot)和Shapiro-Wilk檢驗。
11.9.1 分位數對分位數圖
檢查樣本資料是否違反常態性條件的一種方法是繪製“Q-Q圖”(分位數對分位數圖,Quantile-Quantile plot),這種視覺化方法讓任何系統性非常態資料現形,讓研究者直接檢查。每個觀察值在Q-Q圖都是以一個單獨的點顯示,如同 圖 11.20 是從理論的常態分佈生成的隨機數值做為資料,所繪製形成的Q-Q圖。x軸的數值是各觀察值的理論分位數,以樣本估計平均值和離均差計算的標準化殘差(Standardized Residuals);y軸的數值是各觀察值的實際分位數。如果資料是常態的,所有點應該排列成一條直線。 x軸是觀察值在資料常態分佈(用樣本估計均值和方差)的情況下應該落入的理論分位數,y軸是資料在樣本中的實際分位數。如果資料是常態的,點應該形成一條直線。
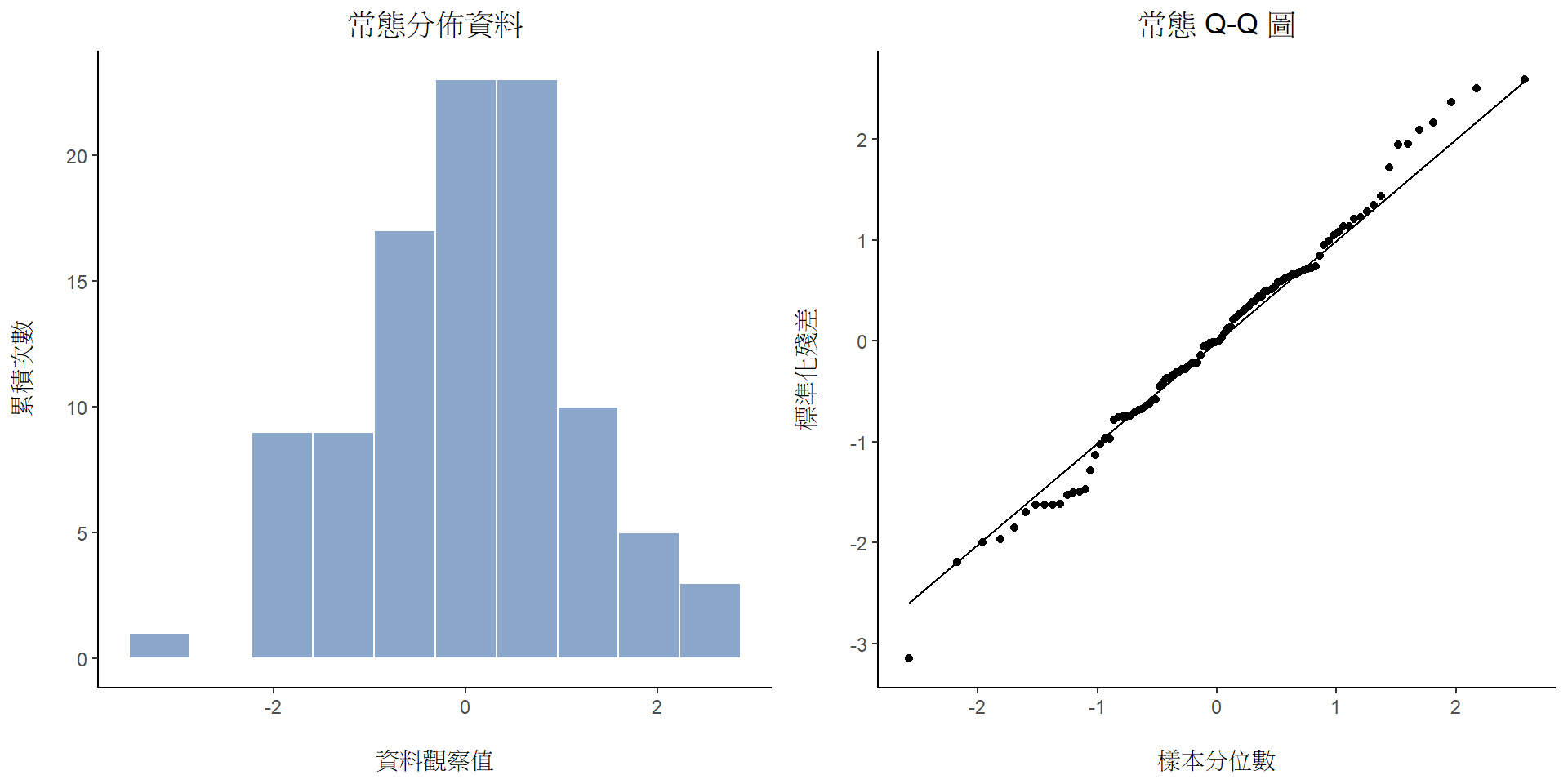
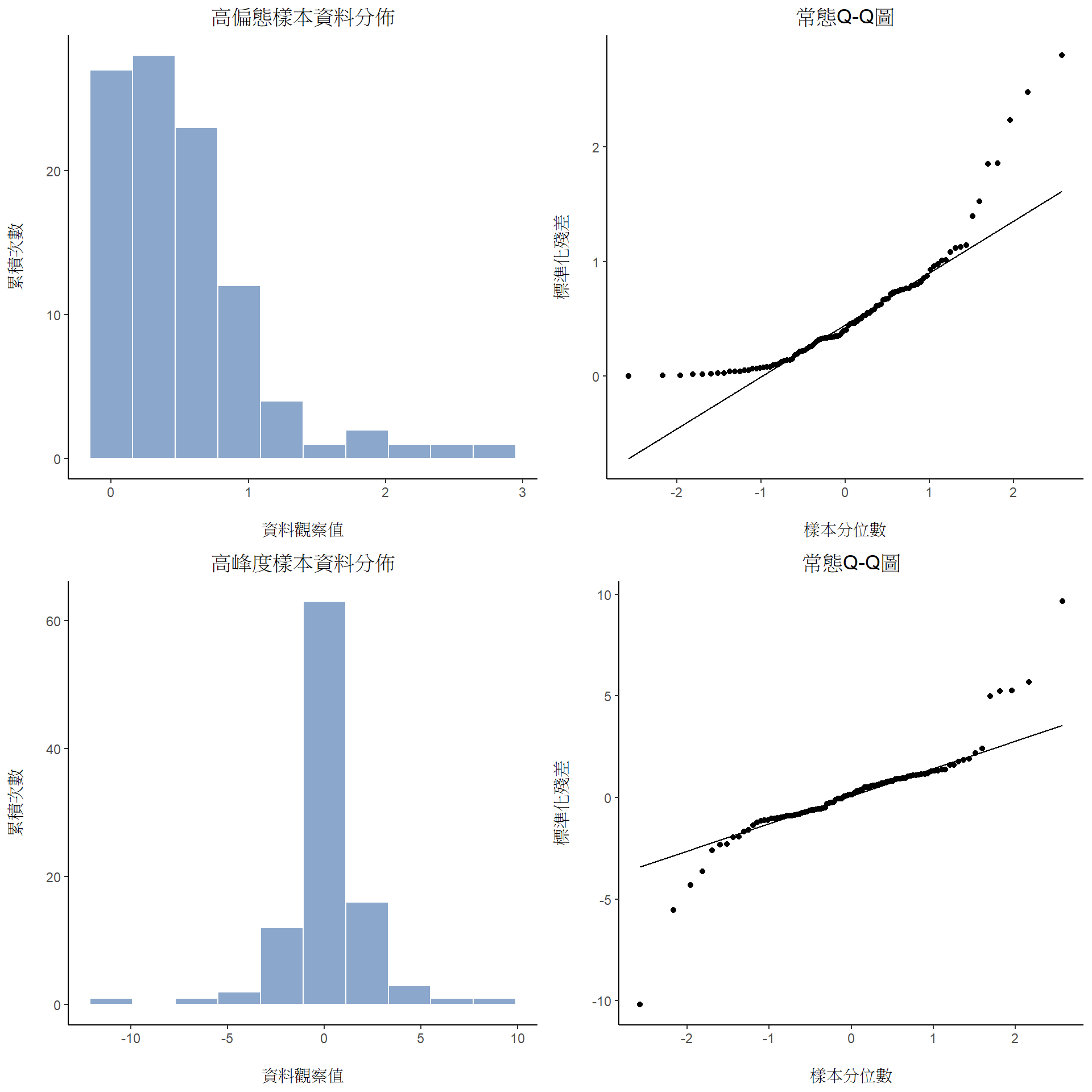
圖 11.20 的資料點都貼合一條直線,這個結果並不奇怪,因為構成的資料是由理論常態分佈隨機生成的。對照 圖 11.21 的另外兩筆資料,構成第一列的直方圖和Q-Q圖之多數資料點都是接近測量尺度的最小值或最大值,使得Q-Q圖向上彎曲;構成第二列的直方圖和Q-Q圖的資料有大量極端值,值得Q-Q圖的中間扁平化,但是兩端急劇彎曲。
11.9.2 t檢定的分位數對分位數圖
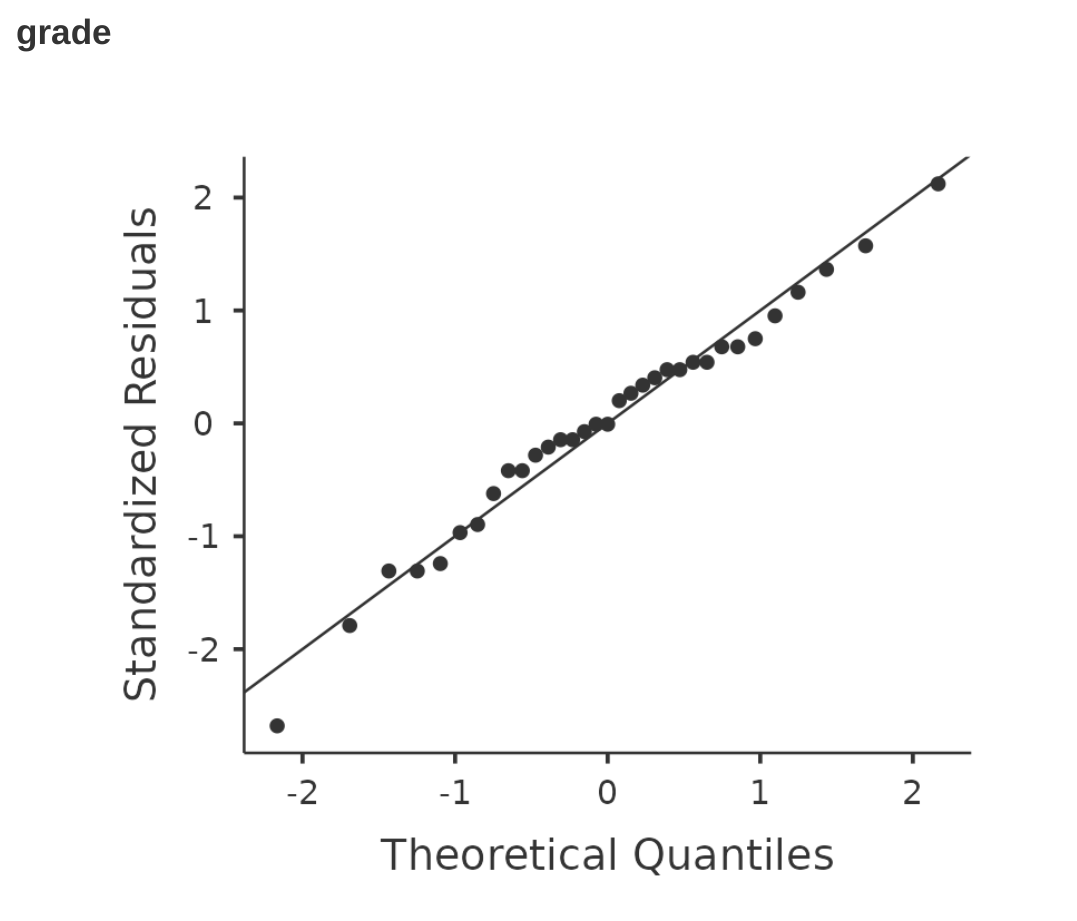
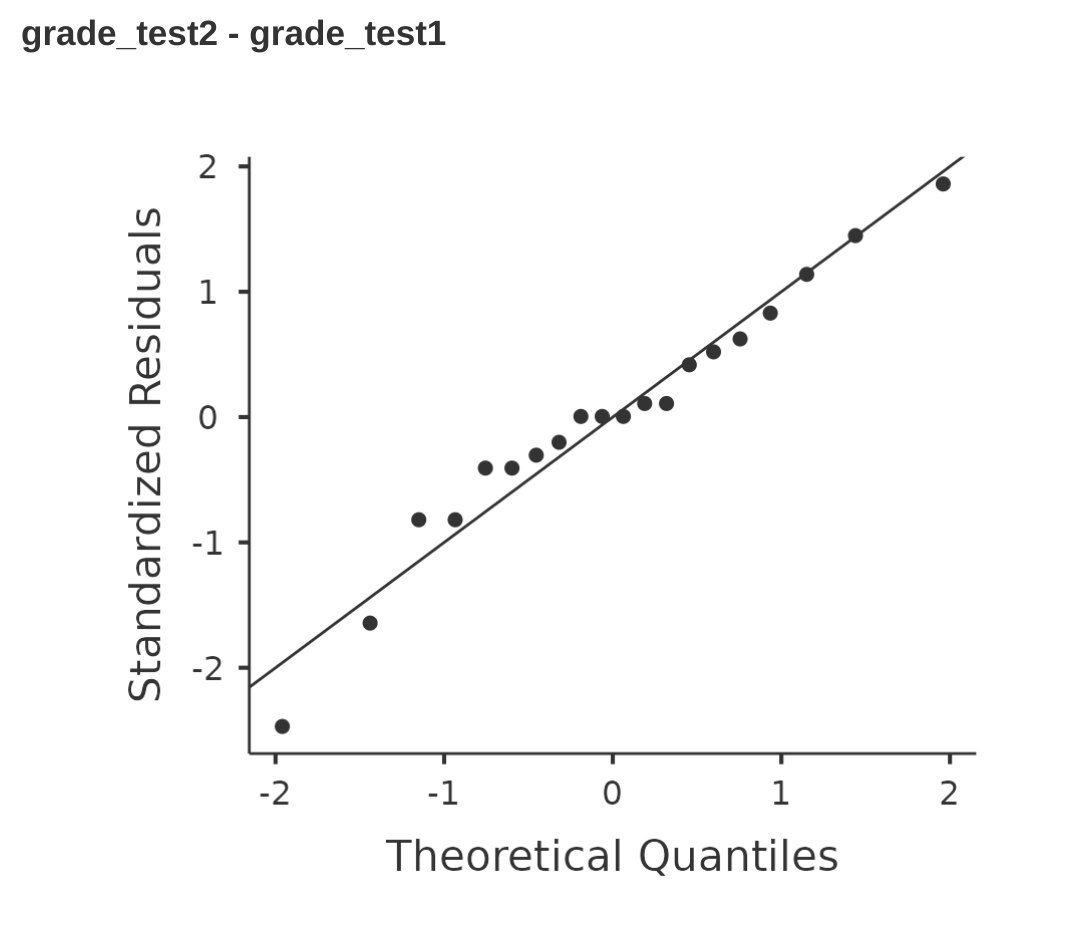
至此為止的jamovi t檢定分析展示,包括 獨立樣本t檢定(圖 11.10)和相依樣本 t 檢定(圖 11.16)。jamovi的分析模組都有提供顯示標準化殘差(Standardiized Residuals)對應理論常態分佈分位數(Theoretical Quantiles)的 Q-Q 圖選項,這是檢查常態性條件的較佳方法。當我們選擇這個選項時,會得到 圖 11.22 和 圖 11.23 顯示的 Q-Q 圖。這裡的解釋是,兩張圖都顯示標準化殘差的分佈基本上符合常態性,我們可以放心繼續進行t檢定!
11.9.3 Shapiro-Wilk檢定
Q-Q圖是一種非正式檢查資料常態性的好方法,若是需要做更正式的檢驗,Shapiro-Wilk檢定(Shapiro & Wilk, 1965)是較正式的檢驗工具。23讀者如果已經了解假設檢定的思維,這裡的虛無假設設定一組\(n\)個觀測值分佈符合常態分佈。
[其他技術細節 24]

要在jamovi的t檢定報名獲得Shapiro-Wilk檢定的統計值,在模組視窗的次標題’Assumptions’之下,找到’Normality’ 下的選項。以構成 圖 11.20 的100筆隨機數值來說,Shapiro-Wilk檢定的\(W = 0.99\),\(p\)值是0.54。所以,我們沒有證據主張這份資料不符合常態性。在一般報告呈現Shapiro-Wilk檢定的結果,研究者必須要用統計值符號\(W\)以及p值,儘管樣本量\(n\)會影響樣本分佈,這裡必不需要一起呈現(因為與t檢定報告的\(n\)是一樣的)。
11.9.4 檢測樣本常態性的範例
若是認為樣本資料不符合常態的適用條件時,可以使用Q-Q圖和 Shapiro-Wilk 檢定確認看看。這裡用澳式足球聯賽(AFL)勝隊分數資料做示範,回憶一下 單元 4 的範例,這筆資料看起來不像符合常態分佈。畫成Q-Q圖會像 圖 11.25 。
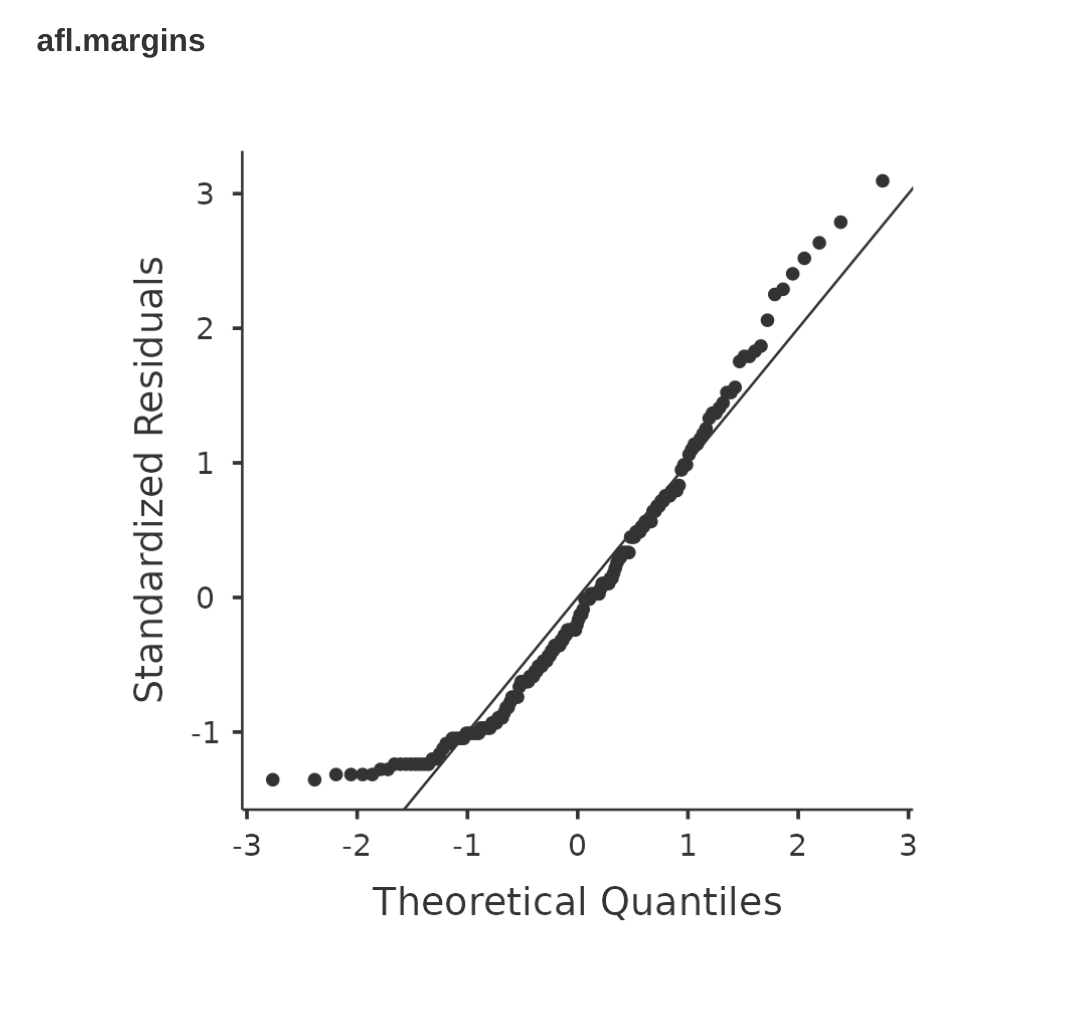
以 AFL margins 資料執行 Shapiro-Wilk 檢定,會得到檢定統計量\(W = 0.94\),p值 = \(9.481\)x\(10^{-07}\)。顯然是顯著地違反常態分佈!
11.10 平均值的無母數統計檢定
如果資料真的不符合常態性,我們還能使用t檢定嗎?現實的資料分析很可能遇到這種狀況。以澳洲足球聯賽(AFL)例行賽勝隊分數資料來說,Shapiro-Wilk 檢定明顯呈現這份資料已不符合常態性。這個案例就需要Wilcoxon檢定了。
如同t檢定,Wilcoxon檢定有單一樣本及獨立樣本兩種形式,都是用在無法精確地使用t檢定分析對應的兩種研究設計。另一方面,Wilcoxon檢定不像t檢定一定需要是符合常態性的資料分佈,才能進行分析。其實,Wilcoxon檢定完全沒有任何資料分佈的適用條件。這種特性,讓這類檢定方法在統計學界得到無母數統計檢定的通稱。雖然不必在意常態性很方便,使用這方法的研究者也要付出代價:就是Wilcoxon檢定的結果檢定力通常比t檢定低,也就是型二錯誤率會變高。以下不會介紹太多Wilcoxon檢定的細節,但會給讀者一些簡單說明。
11.10.1 單一樣本的Wilcoxon檢定
要如何執行單一樣本 Wilcoxon 檢定或者相依樣本 Wilcoxon 檢定呢?這裡使用的範例資料集是happiness,收集修統計課程學生的幸福感問卷。資料集的變項包括每個學生上課前和上課後的幸福感分數,以及兩次測量差距的變化分數。如同 t 檢定的示範,以上課前後的分數進行相依樣本檢定,和以變化分數進行單一樣本檢定的結果是一樣的。同t檢定的程序,最簡單的執行方式是先做標記,這次要將大於零的變化分數,與所有變化分數表列標記,得到的表格如 表 11.4 。
| all differences | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| \(-24\) | \(-14\) | \(-10\) | 7 | \(-6\) | \(-38\) | 2 | \(-35\) | \(-30\) | 5 | |||
| æ£å·®ç°å¼ | 7 | . | . | . | \( \checkmark \) | \( \checkmark \) | . | \( \checkmark \) | . | . | \( \checkmark \) | |
| 2 | . | . | . | . | . | . | \( \checkmark \) | . | . | . | ||
| 5 | . | . | . | . | . | . | \( \checkmark \) | . | . | \( \checkmark \) | ||
這個範例的Wilcoxon符號等級檢定統計值是\(W=7\),採用雙側檢定,能判斷統計值大小是否能充分拒絕虛無假設。用有 jamovi 中執行檢定,只要在“One-sample t Test”分析設定區的Tests之下,勾選“Wilcoxon rank”,就會得到 \(W=7\),p-value=\(0.03711\)等结果。所以我們得到一個顯著的效果,修讀統計學顯然影響學生的幸福感。而且,改用相依樣本檢定並不會給我們不同的答案,請參考 圖 11.26 。
11.10.2 獨立樣本的曼-惠特尼U檢定
最後來介紹曼-惠特尼U檢定(Mann-Whitney U test),這裡介紹的程序比單一樣本Wilcoxon 檢定還要簡單。這裡用awesome資料集做示範,內容是10個人在某個測試的得分,因為原作者已經懶得編故事,就假想這是一個”超讚指數測試”,要比較A與B兩組人那一組最厲害。除了代表每個人的ID之外,還有兩個變項:scores和group。
只要結果不是平手,也就是有兩組人得到的分數完全相同,測試程序就非常簡單。首先只需要建立一個如 表 11.5 的表格,依編號順序比較A組和B組的每一對分數,只要看到A組某人的分數大於B組的某人,就打個勾。
| group B | ||||||
|---|---|---|---|---|---|---|
| 14.5 | 10.4 | 12.4 | 11.7 | 13.0 | ||
| group A | 6.4 | . | . | . | . | . |
| 10.7 | . | \( \checkmark \) | . | . | . | |
| 11.9 | . | \( \checkmark \) | . | \( \checkmark \) | . | |
| 7.3 | . | . | . | . | . | |
| 10 | . | . | . | . | . | |
然後計算出勾的數量,這得到檢定統計量 U25。U的取樣分佈解釋起來有些複雜,在此略過不提。就這個範例的目的而言,關鍵是U的判讀方式與t檢定或z檢定完全一樣。換句話說,如果採用雙側檢定,當U值非常大或非常小時,就會拒絕虛無假設;如果採用單側檢定,只看U值是過大或過小。
只要使用jamovi的”Independent Samples T-Test”分析模組就能執行。將”scores”設為依變項,“group”設為分組,然後勾選Tests之下的Mann-Whitney U,就能得到\(U=3\)和p值= 0.05556的結果。請參考 圖 11.27 。
11.11 本章小結
- 單一樣本z檢定 用來比對樣本平均值是否不同於母群平均值(各位可考慮跳過)。
- 獨立樣本t檢定用於比較兩組平均值的差異,虛無假設設定兩組平均值相等。實務上會使用適用條件 是兩組變異相同的獨立樣本t檢定,或是兩組變異不同的獨立樣本t檢定(Welch t檢定)。
- 相依樣本t檢定用於比較的資料來自同一個樣本的測量,虛無假設設定兩次測量的平均值相等。分析方法與適用條件與單一樣本t檢定相同。
- 只有事前規劃差異比較方向,單尾檢定 才有真正的意義。
- t檢定的效果量以Cohen’ d的公式計算。
- 我們能使用QQ圖及Shapiro-Wilk檢定檢測樣本常態性
- 如果資料真的違反常態性,你可以使用等級資料的平均值檢定像是曼-惠特尼U檢定,以及Wilcoxon檢定。
根據原作者在私家花園做的非正式實驗發現,相對於地球上其他地區,澳大利亞的原生植物只能適應低度磷肥,如果你在當地買了一間種植大量外來種植物的房子,還想種本土植物的話,請先把兩種植物分開;對歐洲植物有營養的肥料對澳大利亞原生植物來說是毒藥。↩︎
一開始匯入資料後, \(X\) 的測量尺度要更改為「連續」(Continuous),因為jamovi 預設功能會將這些成績數值自動定義為名義尺度,這樣子做的分析會不正確。↩︎
採用 小單元 7.5 的符號表示法,統計學家通成寫成:\[X \sim Normal(\mu_0,\sigma^2)\]↩︎
換句話說,如果虛無假設成立,平均值的取樣分佈可以寫成:\[\bar{X} \sim Normal(\mu_0,se(\bar{X})) \]↩︎
實際上,這種說法可能太過武斷。嚴格來說,z檢定僅要求樣本平均值的分佈符合常態分佈。如果母群分佈是常態的,那麼樣本平均值的分佈自然也會是常態的。然而,正如中心極限定理這一節( 小單元 8.3.3 )學到的,即便母群分佈本身不是常態的,樣本平均數的分佈還是能符合常態分佈(這種情況還相當常見)。不過,考慮到假定已知母群標準差是不合理的條件,詳細探討這個條件並無太大必要!↩︎
其實這道難題的解法不完全是一個人的功勞。就原作者所知,最早由數學家高斯提出一部分解法,最終版本的解法是由羅納德·費雪爵士完成。↩︎
更常見的報告問題是,只有數字而沒有任何解釋和詮釋,這樣的報告品質不見得有比較好。原作者認為,如果報告作者沒有努力向讀者解釋和詮釋他們的分析,那麼作者自己可能不夠理解,或者只想偷懶。想知道能看懂統計報告的讀者眼睛是雪亮的,但並非有耐心。只要能幫助讀者理解報告重要,請不要增加閱讀報告的難度。↩︎
技術性的註解:與 z 檢定的適用條件一樣的方式,我們可以削弱 t 檢定的適用條件,只專注取樣分佈。但是,對於 t 檢定,這樣做比較困難。如同z檢定,我們可以將母群常態性的條件替換為樣本平均數的取樣分佈符合常態分佈。然而,我們還要靠樣本標準差做為母群標準差的估計值,因此我們還需要 \(\hat{\sigma}\) 的取樣分佈符合卡方分佈的條件 。這使得判斷是否適用變得更麻煩,因此這個方案很少用在分析實務。幸運的是,如果母群分佈是常態的,這兩個條件都可以滿足。↩︎
正是因為單一樣本t檢定很容易學,原作者才會用這套方法帶各位入門。↩︎
這種研究問題總是會出現一個有趣的問題:在這種情況下,究竟是指哪個母群?是真正修 Harpo 老師課程的所有33位學生?所有可能會修這門課的潛在學生?還是有其他考慮?我們所選擇對象,會影響分析條件嗎?在許多行為統計學的課堂,這個問題幾乎總是被含混帶過,因為每年我的學生都會問我這個問題,所以我會給一個簡單的回覆。就技術來說,母群條件會有影響的。只要“真實世界”母群的定義改變了,就會改變樣本平均值 \(\bar{X}\) 的取樣分佈。能使用t 檢定的必要條件之一觀察值是從一個無限大的母群隨機取樣,然而真實的研究很少符合這個條件,造成t 檢定的結果可能導致錯誤的結論。不過在實際運用時,這個問題並不嚴重。即使無法完全滿足這個條件,多數檢定結果也不至於錯得離譜,所以通常不會太在意這個問題。↩︎
加權值的數學公式通常是:\[w_1=N_1-1\] \[w_2=N_2-1\] 對每個樣本分配加權值之後,就能用兩個變異數估計值的加權,\(\hat{sigma}_{1}^{2}\) 和 \(\hat{sigma}_{2}^{2}\),計算變異數的加權估計值。\[\hat{\sigma}_p^2=\frac{w_1\hat{\sigma}_1^2+w_2\hat{\sigma}_2^2}{w_1+w_2}\] 最後再取估計值的平方根,將加權變異數估計值轉換為加權標準差估計。\[\hat{\sigma}_p=\sqrt{\frac{w_1\hat{\sigma}_1^2+w_2\hat{\sigma}_2^2}{w_1+w_2}}\] 在這個方程式中代入 \((w_1 = N_1 - 1)\) 和 \(w_2 = N_2 - 1\),會得到一個非常醜陋的公式。這個公式似乎是描述加權標準差估計值的“標準”公式,但這不是我偏好思考加權標準差的方法。
我喜歡的思考方式是,這份資料集來自 N 個觀測值,再被分成兩組。所以,可以用 \(X_{ik}\) 代表第 k 位助教帶的第 i 位學生的成績。也就是說,\((X_{11}\) 是 Anastasia 帶的第一位學生成績,\(X_{21}\) 是她帶的第二位學生,以此類推。如此會有兩個不同的組平均值 \(\bar{X}_1\) 和 \(\bar{X}_2\),使用 \(\bar{X}_k\) 就能指稱這兩組,也就是第 k 輔導班的平均成績。
還能跟上的話,我們繼續談離均差:由於每位學生必參加其中一班,就可以將每位學生成績與平均的差異寫成\[X_{ik}-\bar{X}_k\] 那為什麼不使用這套符號代表每位學生的成績與所在輔導班的平均成績之差異?請記住,離均差平方只是一群離均差平方後的平均值,所以可以用這個數學式子表達:\[\frac{\sum_{ik}(X_{ik}-\bar{X}_k)^2}{N}\]
其中符號\(\sum_{ik}\)是一種偷懶的記號方式,意思是“加總每個班的所有學生成績”,因為每個”\(_{ik}\)“對應一位學生。\(^a\) 但是,正如 單元 8 學到的,除以 \(n\) 算出的變異數是一個有偏誤的樣本變異數估計值。因此,我們需要除以 \(n - 1\) 以修正偏誤。同時也提到,這種偏誤的來源是變異數估計依賴於樣本平均值,並且如果樣本平均值不等於母群平均值,極可能造成變異數估計值的系統性偏誤。但是在獨立組設計,一共有兩個樣本平均值!這是否表示會有更大的偏誤?是的,沒錯。所以這裡需要除以 \((n-2)\) 而不是 \((n-1)\),才是計算變異數估計值的正確方法。所以公式要改成:\[\hat{\sigma}_p^2=\frac{\sum_{ik}(X_{ik}-\bar{X}_k)^2}{N-2}\] 最後再取平方根,就會得到加權標準差的估計值 \(\hat{\sigma}_p\)。所以說,加權標準差的計算方法並不特別,與計算單一樣本標準差的方式沒有太大不同。
—
\(^b\) 更正式的符號將在 單元 13 介紹。↩︎只要這兩組樣本的標準差確實相等,標準誤的估計值公式就是 \[SE(\bar{X}_1-\bar{X}_2)=\hat{\sigma}\sqrt{\frac{1}{N_1}+\frac{1}{N_2}}\] 所以 t 統計值的公式是 \[t=\frac{\bar{X}_1-\bar{X}_2}{SE(\bar{X}_1-\bar{X}_2)}\]↩︎
譯註~此圖以jamovi 2.6.23.0重製,常態性檢定與變異同質性檢定在此版已簡化為只呈現Shapiro-Wilk與Lavene’s的結果。↩︎
嚴格來說,應該是指「平均數的差異樣本」呈現常態分佈,但是如果兩個組別的資料都呈現常態分佈,那麼平均值的差異也會呈現常態分佈。實際上,中央極限定理告訴我們,兩個樣本平均值的分佈,會隨著樣本量的增加,將會趨近常態分佈,而不論底層資料的實際分佈是什麼。↩︎
嗯,我猜有讀者有辦法將蘋果和橙子攪在一起,做出一杯美味的綜合果汁。但是,沒有人真正會認為能從綜合果汁能嚐出攪拌前的原味,對吧?↩︎
使用者依然有可以樣本平均值差異,計算估計標準誤的公式,只是和Student t檢定的版本很不一樣: \[SE(\bar{X}_1-\bar{X}_2)=\sqrt{\frac{\hat{\sigma}_1^2}{N_1}+\frac{\hat{\sigma}_2^2}{N_2}}\] 解釋為什麼要這樣算就超出了本書的範圍。對以本書學習統計的讀者來說,必須要知道的是 Welch’s t檢定的 t 統計值與 Student t檢定的 t 統計值略有不同。↩︎
重覆測量非常類似 小單元 10.7 介紹的麥內瑪檢定所適用的研究問題。這並不奇怪,兩者都是標準的重覆測量設計,每個樣本都有兩次測量。唯一的區別是這裡的結果變項是等距尺度(工作記憶容量),而不是名義尺度(是非題)。↩︎
至此已經登場的老師有 Harpo、Chico和 Zeppo。雖然沒有贈品,讀者可以猜猜看 Groucho 會在那裡登場。↩︎
將Cohen’s \(d\)乘以\(\frac{(N - 3)}{(N - 2.25)}\),就是Hedges’ g。↩︎
有興趣的讀者可以自行查看chico2.omv的成果。(註)現在有模組
jReshape及jTransform可讓使用者轉換資料結構。↩︎這裡的描述其實過度簡化。↩︎
另一種可用的方法是Kolmogorov-Smirnov檢驗,這種方法的判定水準應該比Shapiro-Wilk更嚴格。雖然大部分文獻似乎都主張Shapiro-Wilk是更好的常態性檢核工具,但是Kolomogorov Smirnov是一種通用的分佈性質檢核方法,可以應對其他類型的分佈性質檢驗。在jamovi所提供的選項,Shapiro-Wilk檢驗是首要選項。↩︎
*Shapiro-Wilk檢定的統計量通常寫做\(W\),計算步驟是。(1)按照數值大小的遞增順序,排序觀測值,使得\(\bar{X_1}\)成為樣本中最小的值,\(X_2\)成為第二小的值,依此類推。(2)用以下公式計算\(W\)
\[W=\frac{(\sum_{i=1}^N a_iX_i)^2}{\sum_{i=1}^N(X_i-\bar{X})^2}\]
\(\bar{X}\)是所有觀測值的平均值,\(a_i\)值是…由於超出了入門級教材的範圍,以下略。↩︎實際上,有兩種不同的檢定統計量公式,它們之間相差一個常數。這裡所說的是jamovi演算的版本。↩︎