15 因素分析
譯者註 本單元中文內容於2024年1月29日完成編修,jamovi操作示範部分仍持續更新。
前幾個單元介紹的統計檢定方法,主要處理兩個或多個研究組別之間的差異。然而,有時研究目的在於檢視多個變項如何「共變」(co-vary),也就是探討變項之間的關聯,以及這些關聯模式是否呈現出任何有趣且具意義的型態。例如,研究者探索資料的過程中,最有興趣的是有沒有由直接測量的觀察變項所代表的潛在、未被觀察到的潛在因素。符合統計學定義的潛在因素,起初是隱藏的、無法直接觀察的變項,而是透過統計分析,從其他可觀察或者直接測量的變項推斷出來。
這個單元探討數種不同的因素分析及相關技術,首先從探索性因素分析開始。EFA是一種用來識別資料集中潛在因素的統計技術。接著,我們將介紹主成分分析,這是一種資料降維技術,嚴格來說,它並非用來識別潛在因素,而是產生觀察變項的線性組合。隨後,在驗證性因素分析的章節中,將會看到CFA與EFA不同之處:進行CFA時,研究者會從一個既有的概念——即一個模型——出發,該模型描述了資料中變項間的預期關係,然後根據觀察資料來檢驗此模型,並評估其適配度。CFA有一個更複雜的版本,稱為多特質多方法驗證性因素分析,此方法在模型中同時考量潛在因素與方法變異,當研究中使用不同的測量方法時,方法變異便成為一個重要考量,此時這種分析方法就非常有用。最後,我們將介紹一項相關分析:內部一致性信度分析,此分析旨在檢測一個量表測量某個心理構念的穩定程度。
15.1 探索性因素分析
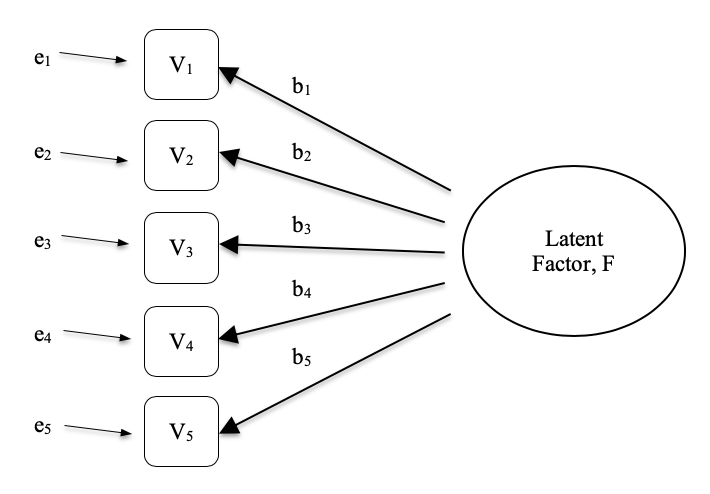
探索性因素分析(EFA) 是一種從觀察資料中推斷出隱藏潛在因素的統計技術。此方法計算一組測量變項(例如 \(V_1, V_2, V_3, V_4\) 和 \(V_5\))在多大程度上可被視為某個潛在因素的測量指標。這種潛在因素無法僅由單一觀察變項測量,而是體現在它所引發的一組觀察變項之間的關係中。
在 圖 15.1 中,每個觀察變項 \(V\) 在某種程度上由潛在因素(\(F\))所「引發」,此影響由係數 \(b_1\) 到 \(b_5\)(也稱為因素負荷)來表示。每個觀察變項也都有一個相關的誤差項 \(e_1\) 到 \(e_5\)。每個誤差項代表相關觀察變項 \(V_i\) 中,無法由潛在因素解釋的變異。
在心理學中,潛在因素代表難以直接觀察或測量的心理現象或構念,例如人格、智力或思維風格。在 圖 15.1 的例子中,我們可能向人們詢問了五個關於其行為或態度的具體問題,從中我們可以描繪出一個稱為「外向性」的人格構念。另一組不同的具體問題,則可能讓我們了解一個人的「內向性」或「盡責性」。
再舉一個例子:我們或許無法直接測量「統計焦慮」,但可以透過問卷中的一組問題來衡量統計焦慮的高低。例如「\(Q1\):完成統計學課程的作業」、「\(Q2\):試圖理解期刊文章中描述的統計數據」以及「\(Q3\):向講師請教課程中不理解之處」等,每個問題都從低焦慮到高焦慮進行評分。統計焦慮程度高的人,在這些觀察變項上傾向於給出一致的高分;同樣地,統計焦慮程度低的人,則傾向於給出一致的低分。
在探索性因素分析(EFA)中,我們實質上是在探索觀察變項之間的相關性,以揭示當觀察變項共同變動時,所顯現出的任何有趣、重要的潛在因素。我們可以使用統計軟體來估計潛在因素,並識別哪些變項在每個因素上具有高負荷量1(例如負荷量 > 0.5),這表示它們是該潛在因素的有效測量指標。此過程包含一個稱為「轉軸」(rotation)的步驟,坦白說這是一個有點奇特的想法,但幸運的是我們不必深入理解其原理,只需知道它有助於讓不同因素上的負荷模式更加清晰。因此,轉軸能幫助我們更清楚地看出哪些變項與每個因素有實質性的關聯。此外,我們還需要決定在我們的資料中,保留多少個因素是合理的,而「特徵值」(Eigen values)在這方面很有幫助。在介紹完EFA的主要假設後,我們會再回頭討論這些概念。
15.1.1 探索性因素分析的執行條件
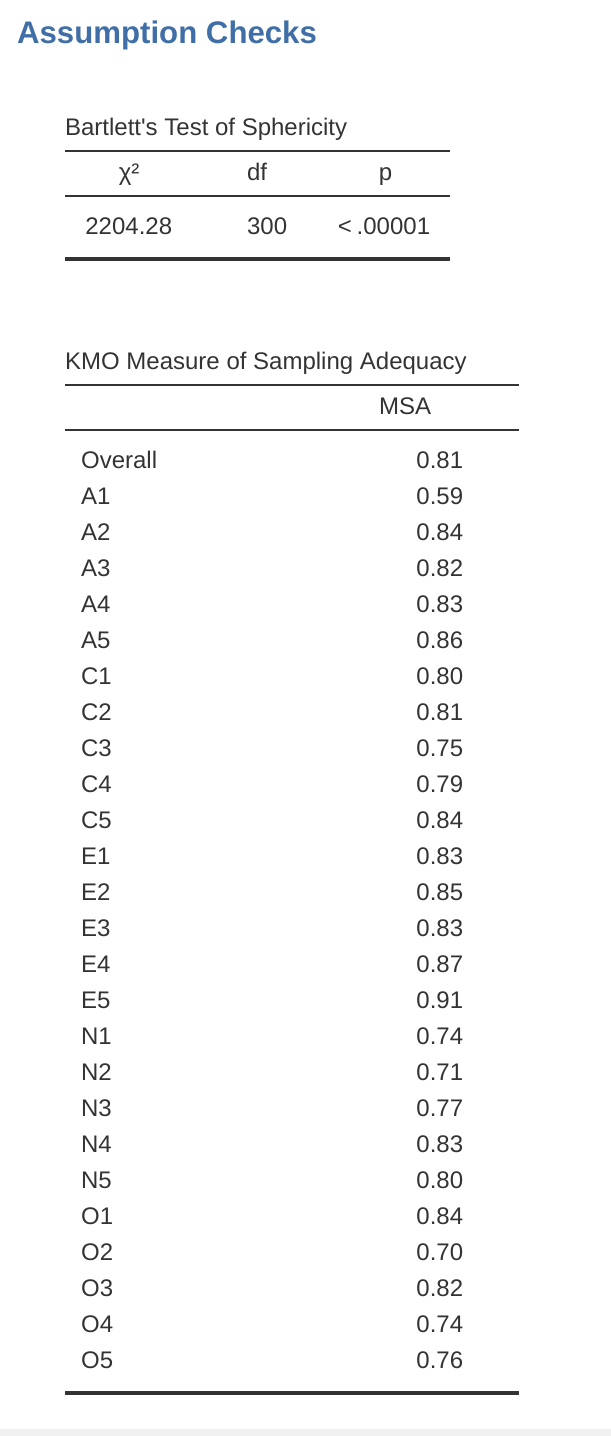
分析過程中需要檢查幾個假設。第一個是球形性(sphericity),它主要檢視資料集中的變項彼此間是否具有足夠的相關性,以致於能被一組較少的因素所概括。巴特利球形檢定(Bartlett’s test for sphericity)檢視觀察到的相關矩陣是否顯著偏離零相關(或虛無)矩陣。因此,如果巴特利檢定結果顯著(\(p < .05\)),表示觀察到的相關矩陣與虛無矩陣有顯著差異,適合進行EFA。
第二個假設是樣本適足性(sampling adequacy),使用凱薩-邁耶-歐金(Kaiser-Meyer-Olkin, KMO)樣本適足性量數(Measure of Sampling Adequacy, MSA)來檢驗。KMO指標衡量觀察變項間的變異,可能為共同變異的比例。KMO運用偏相關來檢視只由兩個項目構成因素的情況。我們幾乎不希望EFA產生許多僅由兩個項目構成的因素。KMO之所以關乎樣本適足性,是因為在樣本不足時,偏相關的數值通常較高。如果KMO指標高(\(\approx 1\)),表示EFA是有效率的;反之,如果KMO低(\(\approx 0\)),則EFA不具參考價值。KMO值小於0.5表示不適合進行EFA,至少應達到0.6才被認為適合。0.5到0.7之間的值被視為尚可,0.7到0.9之間為良好,0.9到1.0之間則為極佳。
15.1.2 探索性因素分析的用途
如果EFA提供了一個良好的解(即因素模型),我們就需要決定如何運用這些新發現的因素。研究人員常在心理測量量表的發展過程中使用EFA。他們會先建立一個他們認為與一個或多個心理構念相關的問卷題庫,然後使用EFA來檢視哪些題目會「共同構成」潛在因素,接著評估是否應移除某些無法有效或清晰測量任何一個潛在因素的題目。
順應此思路,EFA的另一個應用是將對特定因素有高負荷量的變項結合成一個因素分數,有時也稱為量表分數。有兩種方法可以將變項結合成量表分數:
- 根據每個項目對因素的負荷量進行加權,創建一個新的加權分數變項。
- 根據每個對因素有貢獻的項目創建一個新變項,但給予它們相等的權重。
第一種選項中,每個項目對總分的貢獻取決於它與因素的關聯強度。第二種選項中,我們通常直接計算所有對某個因素有實質貢獻的項目的平均值,來創建合併的量表分數變項。選擇哪種方法取決於個人偏好,但第一種選項的缺點是負荷量在不同樣本間可能會有很大差異。在行為與健康科學領域,我們常需要在不同研究和樣本中開發和使用綜合問卷量表分數。在這種情況下,使用基於實質項目均等貢獻的綜合測量是合理的,而不是根據來自不同樣本的特定樣本負荷量進行加權。無論如何,將合併變項的測量理解為項目的平均值,比使用特定於樣本的最佳加權組合更為簡單直觀。
還有一種更進階的統計技術,已超出本書範圍,是進行迴歸建模,其中潛在因素被用來預測其他潛在因素。這稱為「結構方程模型」(structural equation modelling),有專門的軟體程式和R套件可用於此方法。但我們先別操之過急,現在應該專注於如何在jamovi中執行EFA。
15.1.3 使用jamovi完成探索性因素分析
首先,我們需要一些資料。圖 15.2 中展示了25個取自國際人格項目庫的自我報告人格題目,這些題目被納入合成孔徑人格評估(SAPA:http://sapa-project.org)的網路人格評估專案中。這25個項目依據五個假定因素進行組織:親和性、盡責性、外向性、神經質性與開放性。
項目資料是透過一個六點反應量尺收集的:
- 非常不準確
- 中度不準確
- 輕度不準確
- 輕度準確
- 中度準確
- 非常準確
資料集 bfi_sample.csv 包含 \(N=250\) 份回覆的樣本。作為研究人員,我們有興趣探索這些資料,看看是否存在一些可由 bfi_sample.csv 資料檔中25個觀察變項合理測量的潛在因素。打開資料集並檢查這25個變項是否被編碼為連續變項(技術上它們是次序變項,但在jamovi中進行EFA時,這通常不影響結果,除非您決定計算加權因素分數,此時則需要連續變項)。在jamovi中執行EFA的步驟如下:
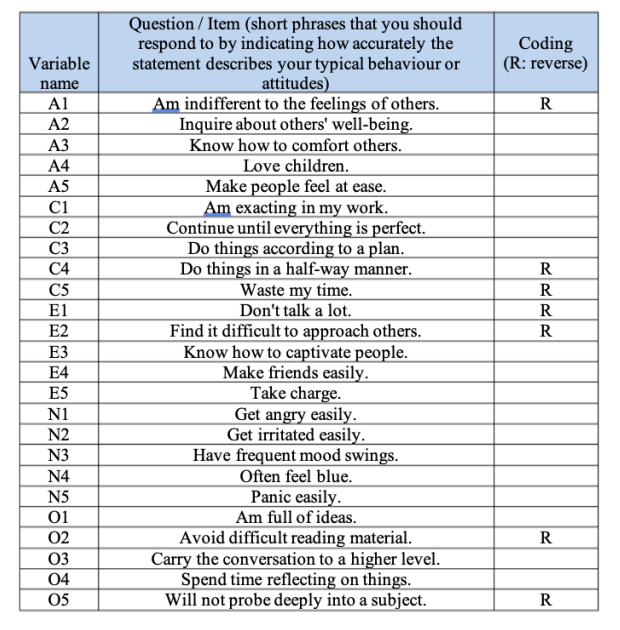
示範資料Personality Questionnaire包括\(N=250\)份參與者樣本。研究人員會有興趣的,是檔案裡的\(25\)個觀察變項,有那些能合理測量的潛在因素。開啟這份檔案後,研究人員會先檢查這\(25\)個變項是否以連續變項編碼?如果不是,至少要用次序變項編碼,雖然jamovi的EFA模組可以處理類別變項。若是要用因素負荷加權計算因素分數,就需要先轉換為連續變項。
接著執行jamovi的EFA模組:
- 從jamovi主功能列選擇「因素分析」(Factor) -> 「探索性因素分析」(Exploratory Factor Analysis),開啟EFA分析視窗(圖 15.3)。
- 選取25個人格問卷題目,並將它們移至「變項」(Variables)框中。
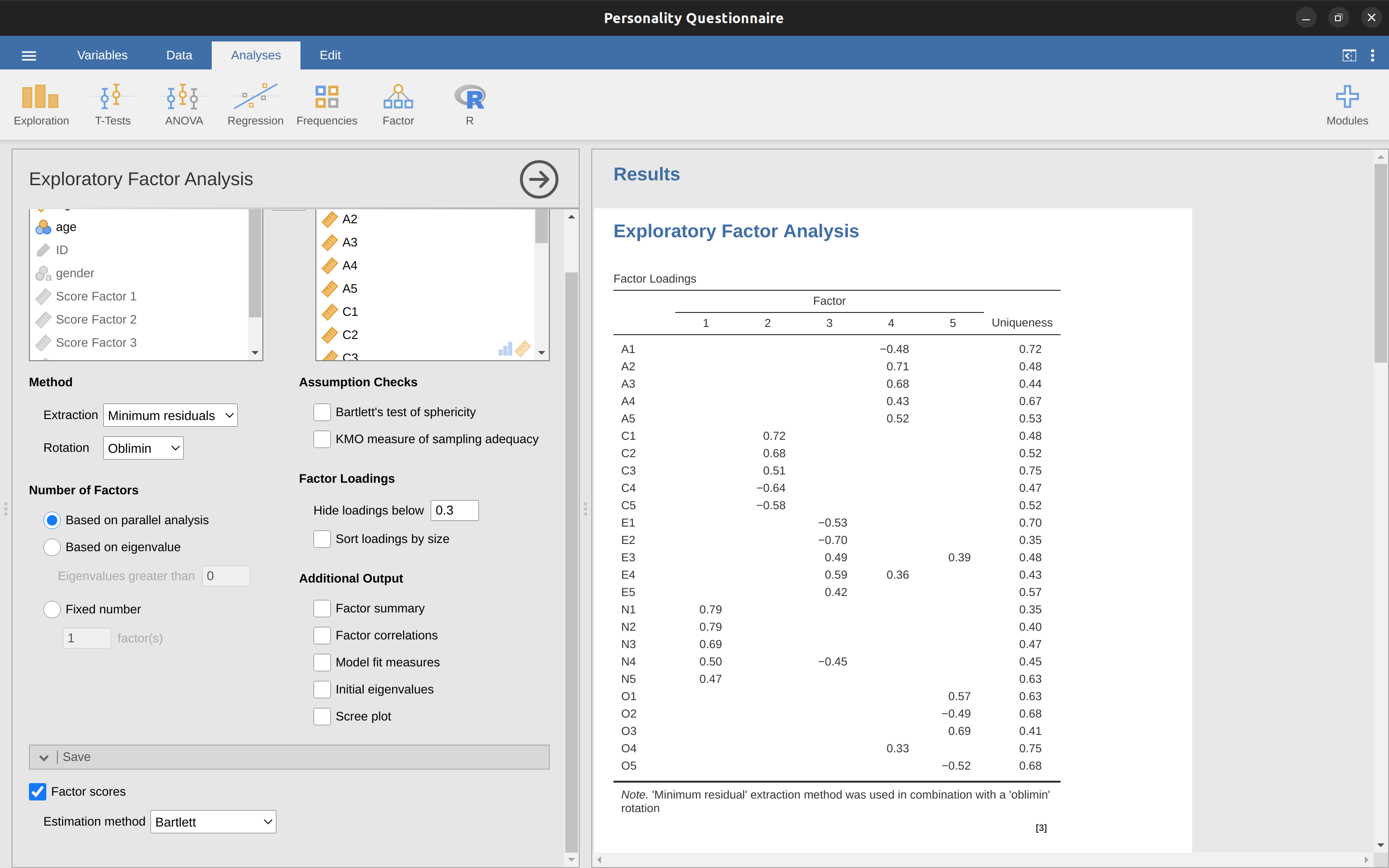
- 勾選適當的選項,包括「假設檢定」(Assumption Checks),以及「轉軸法」(Rotation)的「方法」(Method)、「萃取因素數」(Number of Factors),和「額外輸出」(Additional Output)選項。請參考 圖 15.3 中此範例EFA的建議選項。請注意,研究人員通常會在分析過程中調整轉軸方法和萃取的因素數量,以尋求最佳結果,詳述如下。
首先,檢查假設(圖 15.4)。您可以看到(1)巴特利球形性檢定結果顯著,因此滿足此假設;(2)KMO樣本適足性量數(MSA)的總體值為0.81,顯示樣本適足性良好。到此為止沒有問題!
接下來要檢查的是要使用(或從資料中「萃取」)多少個因素。有三種不同的方法可供選擇:
- 一種慣例是選擇所有特徵值大於1的成分。在我們的資料中,這會產生四個因素(您可以試試看)。
- 檢視陡坡圖(scree plot),如 圖 15.5 所示,可以幫助您識別「拐點」(point of inflection)。這是陡坡曲線斜率在「彎肘」(elbow)下方明顯趨於平緩的點。在我們的資料中,這會產生五個因素。解讀陡坡圖有點像一門藝術:在 圖 15.5 中,從第5個因素到第6個因素有一個明顯的階梯,但在其他陡坡圖中,情況可能不會這麼清晰。
- 使用平行分析技術,將觀察資料得到的特徵值與隨機資料產生的特徵值進行比較。萃取的因素數量是其特徵值大於隨機資料特徵值的因素個數。
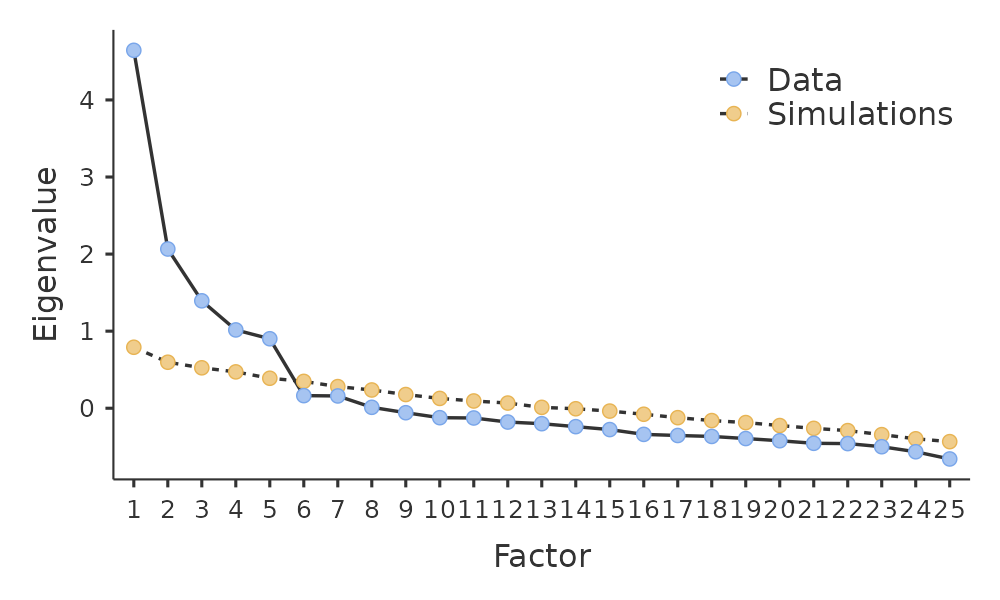
根據 Fabrigar et al. (1999) 的說法,第三種方法是個好方法,儘管在實務上,研究人員傾向於檢視所有三種方法,然後根據最容易或最有助於解釋的因素數量做出判斷。這可以理解為「意義性準則」,研究人員通常除了檢視上述方法之一的解之外,還會檢視多一個或少一個因素的解,然後採納對他們來說最有意義的解。
同時,我們也應該考慮轉軸最終解的最佳方式。轉軸主要有兩種方法:正交轉軸(例如 ‘varimax’)會強制所選因素不相關,而斜交轉軸(例如 ‘oblimin’)則允許所選因素相關。心理學家和行為科學家感興趣的構面通常不是我們預期會是正交的,因此斜交解可以說更為合理2。
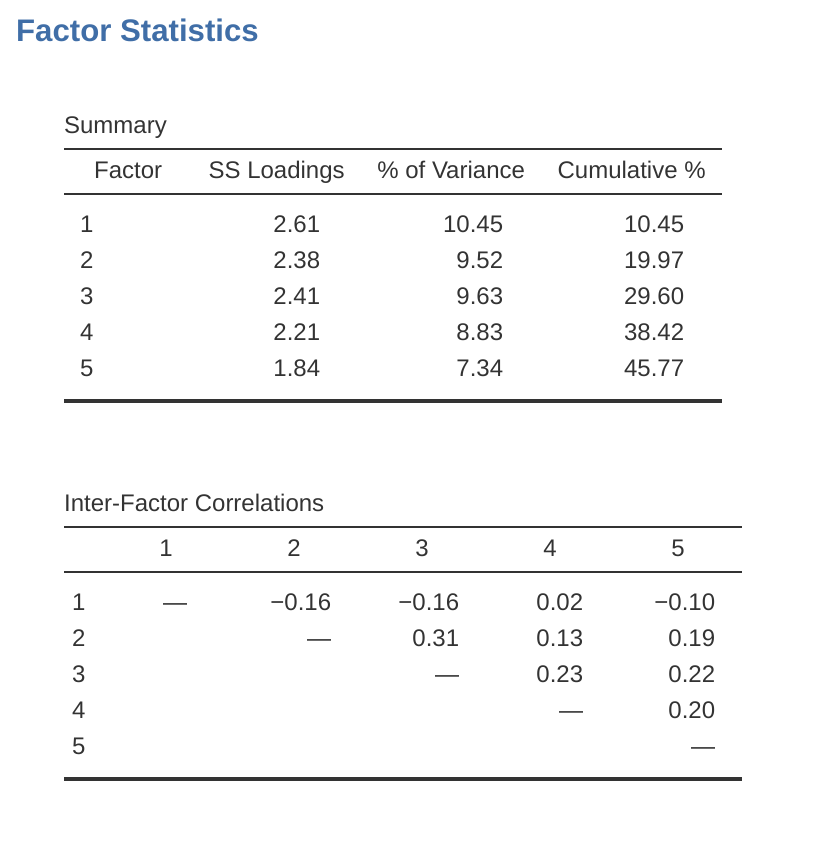
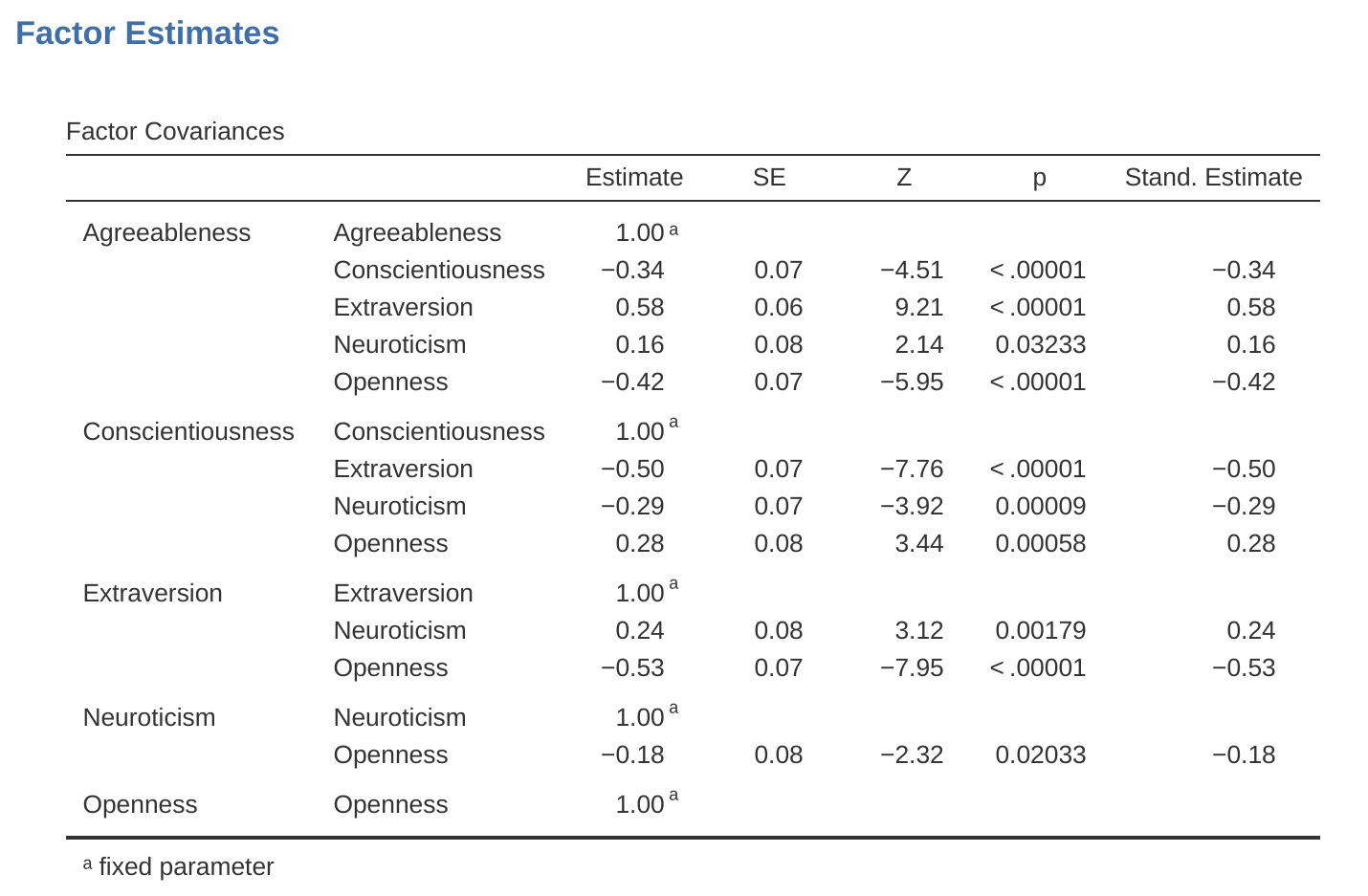
實務上,如果在斜交轉軸中發現因素之間有實質相關(正或負,且 > 0.3),如 圖 15.6 所示,其中兩個萃取因素之間的相關為0.31,這就證實了我們偏好斜交轉軸的直覺。如果因素確實相關,那麼斜交轉軸會比正交轉軸產生對真實因素更好的估計和更佳的簡單結構。反之,如果斜交轉軸顯示因素間的相關接近於零,那麼研究人員可以進行正交轉軸(其結果應與斜交轉軸大致相同)。
檢查萃取因素間的相關性後,發現至少有一個相關大於0.3(圖 15.6),因此偏好對五個萃取因素進行斜交(‘oblimin’)轉軸。我們也可以在 圖 15.6 中看到,五個因素解釋的資料總變異比例為46%。因素一解釋了約10%的變異,因素二到四各約9%,因素五則略高於7%。這並不算太好;如果整體解能解釋資料中更大部分的變異會更好。
請注意,在每次EFA中,您潛在的因素數量可能與觀察變項數量相同,但每增加一個因素,所解釋的變異量就會減少。如果前幾個因素解釋了原始25個變項的大部分變異,那麼這些因素顯然是這25個變項的有用、更簡單的替代品。您可以捨棄其餘的因素而不會損失太多原始的變異性。但是,如果需要18個因素(例如)才能解釋這25個變項的大部分變異,那麼您不妨直接使用原始的25個變項。
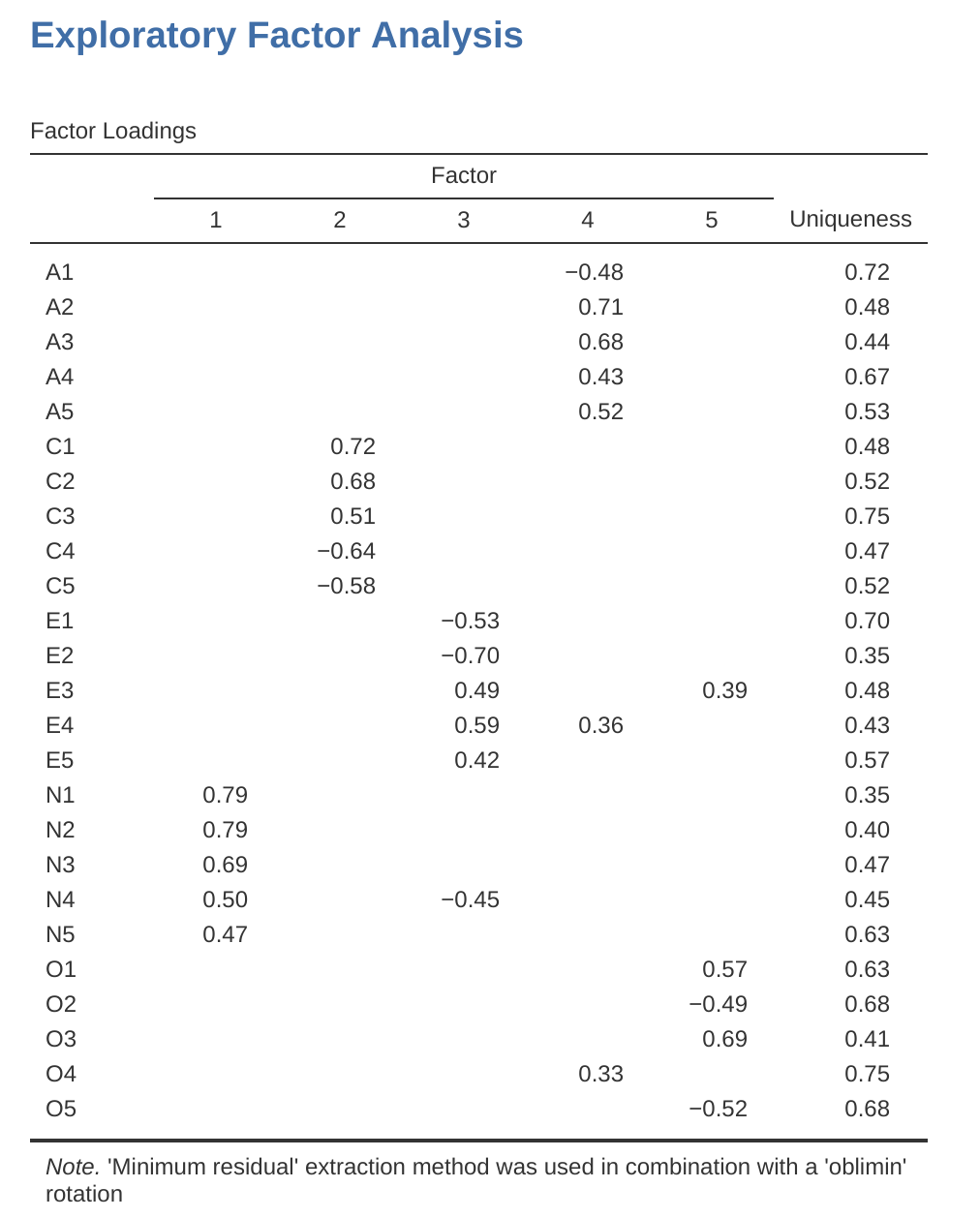
圖 15.7 顯示了因素負荷量,即25個不同的人格項目如何在五個選定的因素上負荷。我們隱藏了小於0.3的負荷量(在 圖 15.3 所示的選項中設定)。
對於因素1、2、3和4,因素負荷的模式與 圖 15.2 中指定的假定因素非常吻合。太好了!因素5也非常接近,五個假定測量「開放性」的觀察變項中,有四個在該因素上有很好的負荷。不過,變項O4似乎不太吻合,因為 圖 15.7 的因素解顯示它負荷在因素4上(儘管負荷量相對較低),而沒有實質性地負荷在因素5上。
另一點值得注意的是,在 圖 15.2 中標示為「R:反向計分」的變項,其因素負荷量為負。看看項目A1(「我對他人的感受漠不關心」)和A2(「我會關心他人的福祉」)。我們可以看到,A1的高分表示低親和性,而A2(以及所有其他「A」開頭的變項)的高分表示高親和性。因此,A1會與其他「A」變項呈負相關,這就是為什麼它的因素負荷量為負,如 圖 15.7 所示。
我們也可以在 圖 15.7 中看到每個變項的「獨特性」(uniqueness)。獨特性是指變項中「獨有」且無法被因素解釋的變異比例3。例如,「A1」中有72%的變異無法由五因素解中的因素解釋。相比之下,「N1」無法被因素解解釋的變異相對較低(35%)。請注意,「獨特性」越高,該變項在因素模型中的相關性或貢獻就越低。
老實說,在EFA中得到如此整潔的解並不常見。結果通常會混亂得多,而且解釋因素的意義也更具挑戰性。很少能有這樣清晰劃分的題庫。更多時候,您會有大量的觀察變項,您認為它們可能是少數潛在因素的指標,但您並不那麼確定哪些變項會歸到哪裡去!
所以,我們似乎得到了一個相當不錯的五因素解,儘管它解釋的觀察總變異比例相對較低。假設我們對這個解感到滿意,並希望在進一步的分析中使用這些因素。最直接的選擇是為每個因素計算一個總體(平均)分數,方法是將對該因素有實質負荷的每個變項的分數相加,然後除以變項的數量(換句話說,為每個人的每個量尺項目創建一個「平均分數」)。例如,對於我們資料集中的每個人,就親和性因素而言,這意味著將 A1 + A2 + A3 + A4 + A5 相加,然後除以54。基本上,我們計算的因素分數是基於每個包含的變項/項目的等權分數。我們可以在jamovi中分兩步完成:
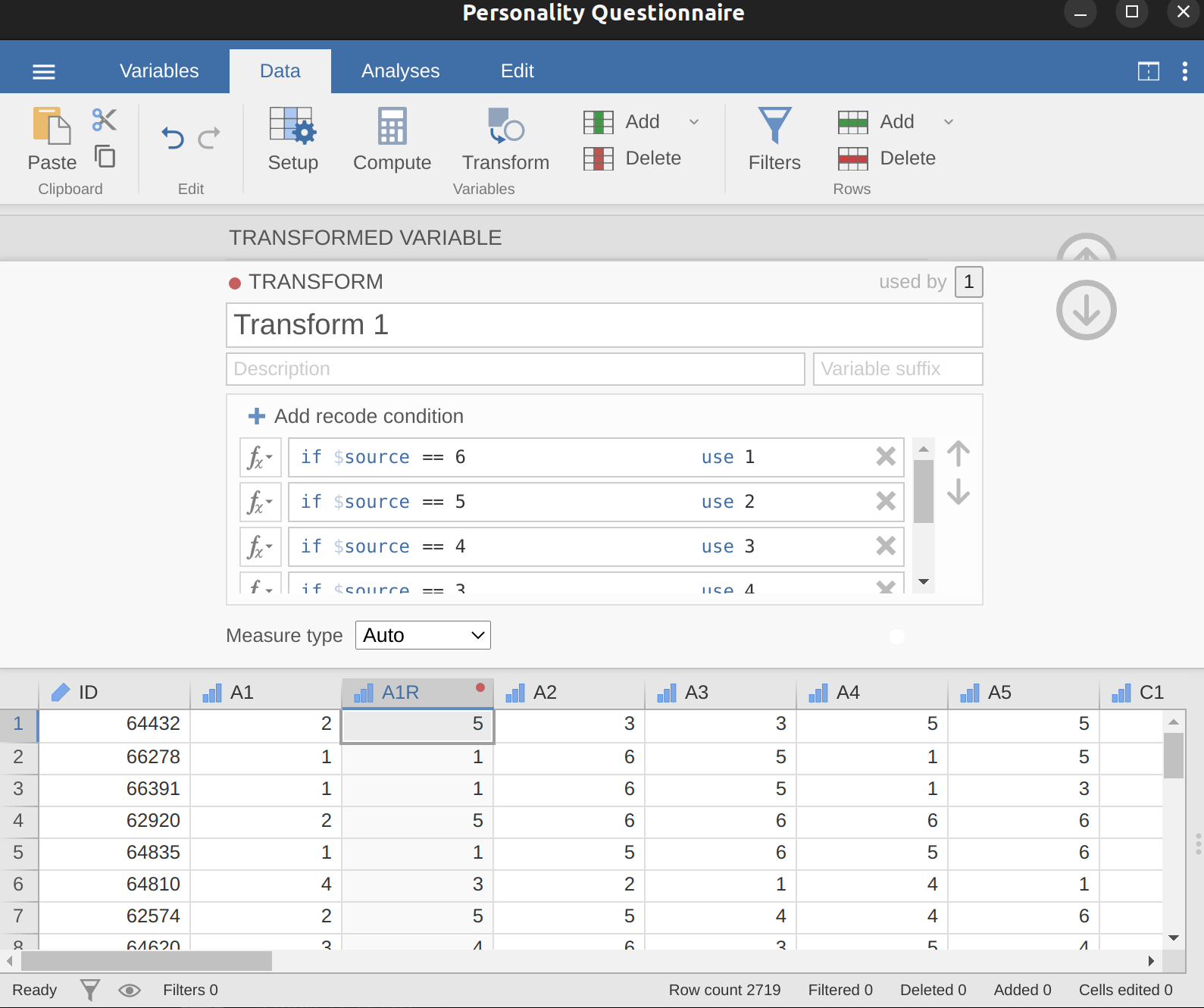
- 使用jamovi的轉換變項指令,將A1反向計分後重新編碼為「A1R」(即 \(6 = 1\); \(5 = 2\); \(4 = 3\); \(3 = 4\); \(2 = 5\); \(1 = 6\))(見 圖 15.8)。
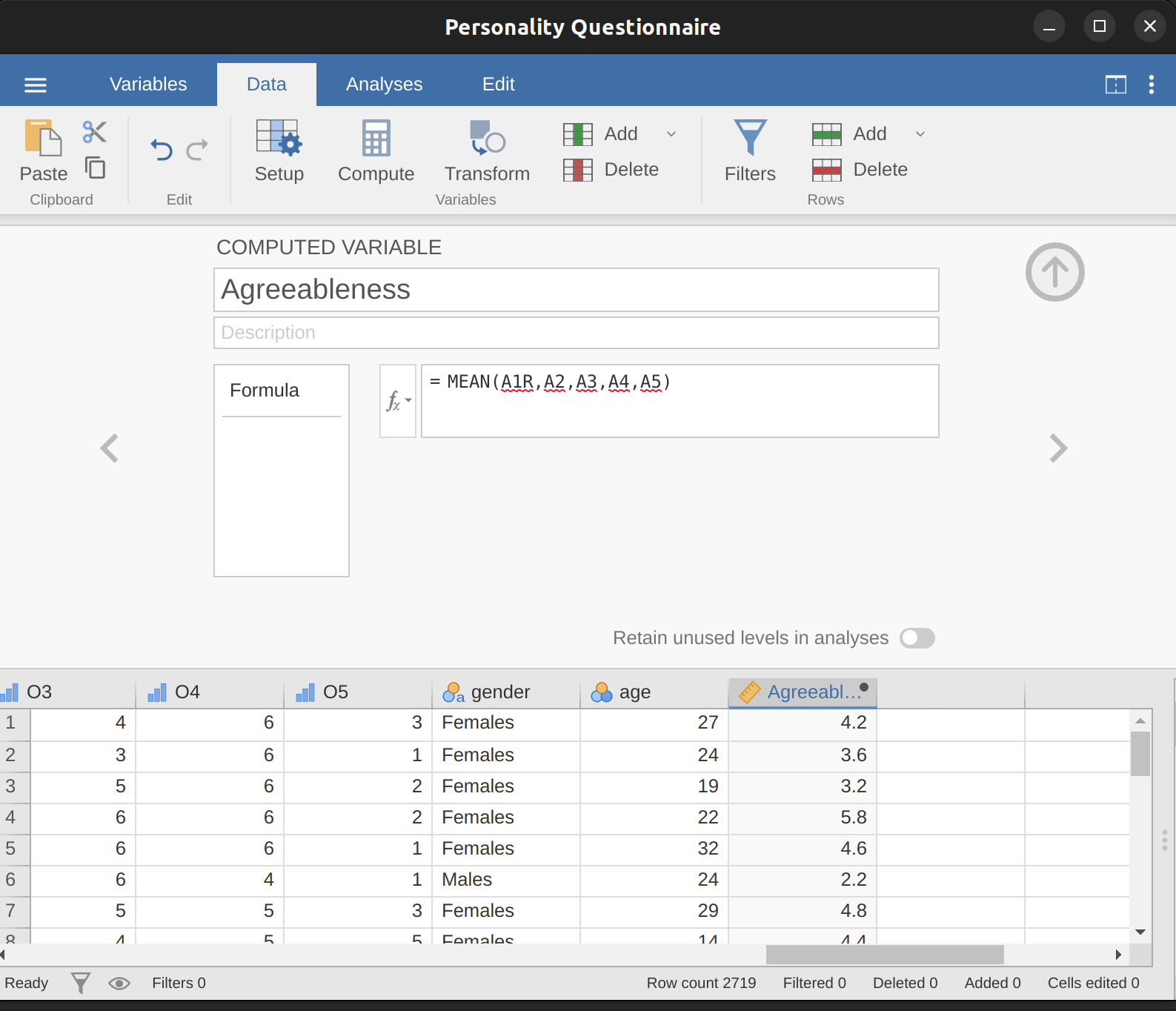
- 使用jamovi的計算新變項指令,計算A1R、A2、A3、A4和A5的平均值,創建一個名為「Agreeableness」的新變項(見 圖 15.9)。
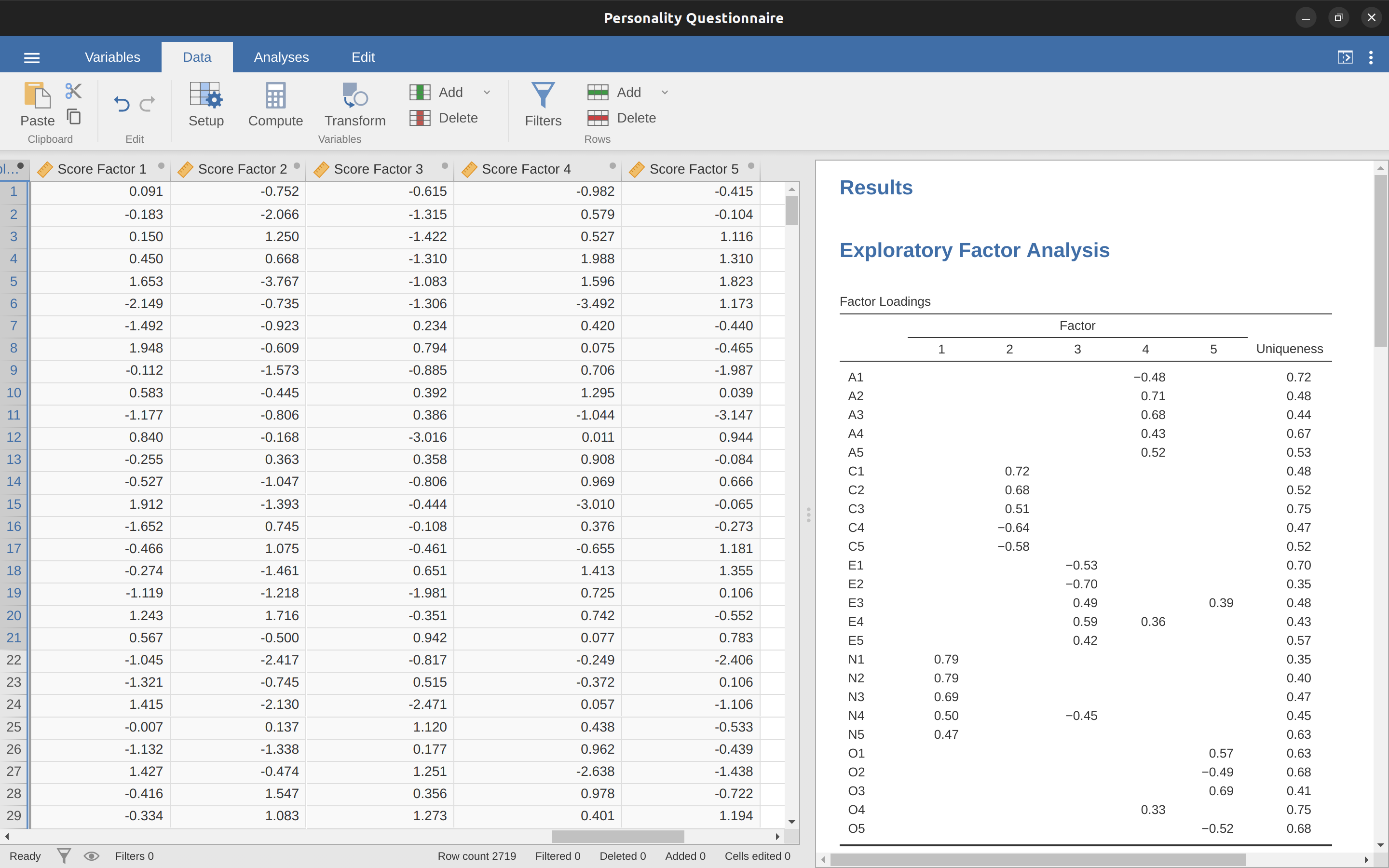
另一個選擇是創建一個最佳加權的因素分數指標。要做到這一點,請使用「儲存」(Save) -> 「因素分數」(Factor scores) 核取方塊將因素分數儲存到資料集中。完成後,您會看到資料中增加了五個新變項(欄),每個萃取的因素各一個。請參見 圖 15.10 和 圖 15.11。
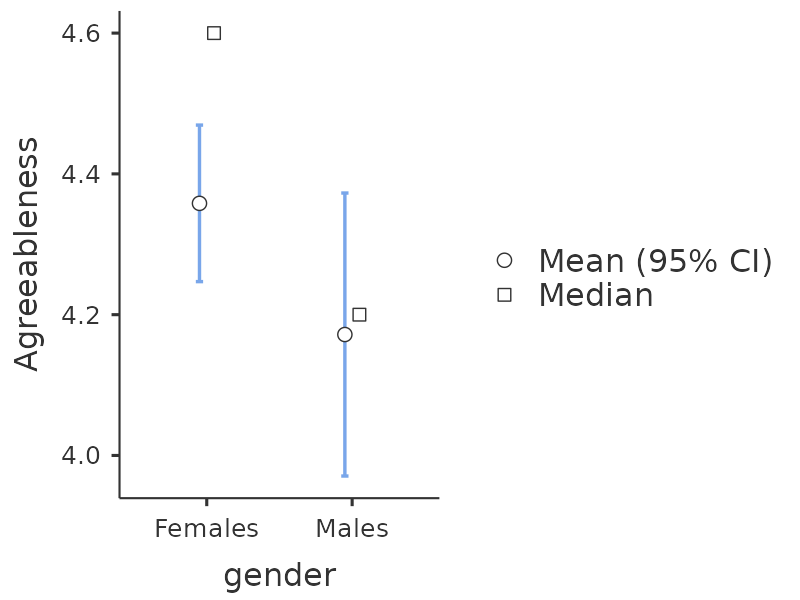
現在,您可以繼續進行進一步的分析,可以使用基於平均分數的因素量表(如 圖 15.9 所示),也可以使用jamovi計算的最佳加權因素分數。任君選擇!例如,您可能想看看我們的人格量表中是否存在性別差異。我們對使用平均分數法計算的親和性分數進行了此項分析,儘管t檢定圖(圖 15.12)顯示男性的親和性低於女性,但此差異不顯著(曼-惠特尼U檢定 \(U = 5768\), \(p = .075\))。
15.1.4 探索性因素分析的報告須知
希望到目前為止,您對EFA以及如何在jamovi中進行EFA有了一定的了解。那麼,完成EFA後,該如何撰寫報告呢?EFA的撰寫沒有正式的標準格式,範例因學科和研究人員而異。儘管如此,報告中仍應包含一些相當標準的資訊:
- 您所研究領域的理論基礎,特別是您有興趣透過EFA揭示的構念。
- 樣本描述(例如,人口統計資訊、樣本大小、抽樣方法)。
- 所用資料類型的描述(例如,名義、連續)及描述性統計。
- 描述您如何檢定EFA的假設。應報告球形性檢定和樣本適足性量數的詳細資訊。
- 說明使用了哪種因素萃取方法(例如,「最小殘差法」或「最大概似法」)。
- 說明決定最終解中萃取多少因素及選擇哪些項目的標準和過程。清晰解釋EFA過程中的關鍵決策理由。
- 說明嘗試了哪些轉軸方法、原因及結果。
- 最終的因素負荷量應以表格形式呈現在結果中。此表也應報告每個變項的獨特性(或共同性)(在最後一欄)。因素負荷量除項目編號外,還應附有描述性標籤。因素之間的相關性也應包含在內,可以在此表的底部或另一個獨立的表格中呈現。
- 應為萃取的因素提供有意義的名稱。您可以使用先前選定的因素名稱,但在檢視實際項目和因素後,您可能會認為不同的名稱更為合適。
15.2 主成分分析
在前一節中,我們看到EFA可用於識別潛在因素。而且,如我們所見,在某些情況下,較少數量的潛在因素可以透過某種組合的因素分數,用於進一步的統計分析。
這樣,EFA就被當作一種「資料降維」技術。另一種資料降維技術,有時被視為EFA家族的一部分,是主成分分析(PCA)。然而,PCA並非用來識別潛在因素,而是從一組較大的測量變項中創建一個線性綜合分數。
PCA僅對原始資料進行數學轉換,對變項如何共變不作任何假設。PCA的目標是計算原始變項的幾個線性組合(主成分),這些主成分可用於總結觀察資料集而不會損失太多資訊。然而,如果分析的目標是識別潛在結構,那麼EFA是更佳的選擇。而且,如我們所見,EFA產生的因素分數可以像主成分分數一樣用於資料降維的目的 (Fabrigar et al., 1999)。
PCA在心理學中因多種原因而普及,因此值得一提。不過,如今由於桌上型電腦的強大運算能力,EFA同樣易於執行,且相較於PCA,尤其是在因素和變項數量較少的情況下,EFA較不易產生偏差。PCA的大部分程序與EFA相似,因此儘管在概念上有些差異,但實際操作步驟是相同的。對於大樣本以及足夠數量的因素和變項,PCA和EFA的結果應該相當類似。
要在jamovi中執行PCA,您只需從jamovi主功能列中選擇「因素分析」(Factor) -> 「主成分分析」(Principal Component Analysis)以打開PCA分析視窗。然後,您可以遵循前面使用jamovi完成探索性因素分析中的相同步驟。
15.3 驗證性因素分析
我們使用EFA從精心挑選的人格題庫中識別潛在因素的嘗試,似乎相當成功。在我們尋求開發一種有用的人格測量工具的下一步,是用不同的樣本來檢驗我們在原始EFA中識別出的潛在因素。我們想看看這些因素是否經得起考驗,是否能用不同的資料來確認它們的存在。這是一個更嚴格的檢驗,我們將會看到。這被稱為驗證性因素分析(CFA),因為我們將尋求確認一個預先指定的潛在因素結構5。
在CFA中,我們不是以探索性的方式分析資料如何組合,而是將一個結構(如 圖 15.13 所示)強加於資料之上,然後看資料與我們預先指定的結構的擬合程度。從這個意義上說,我們是在進行驗證性分析,以檢視一個預先指定的模型在多大程度上被觀察資料所證實。
因此,對人格項目進行直接的驗證性因素分析(CFA)將指定五個潛在因素,如 圖 15.13 所示,每個因素由五個觀察變項測量。每個變項都是一個潛在因素的測量指標。例如,A1由潛在因素「親和性」預測。而且因為A1不是親和性因素的完美測量,所以有一個與之相關的誤差項 \(e\)。換句話說,\(e\) 代表了A1中無法被親和性因素解釋的變異,這有時被稱為測量誤差。
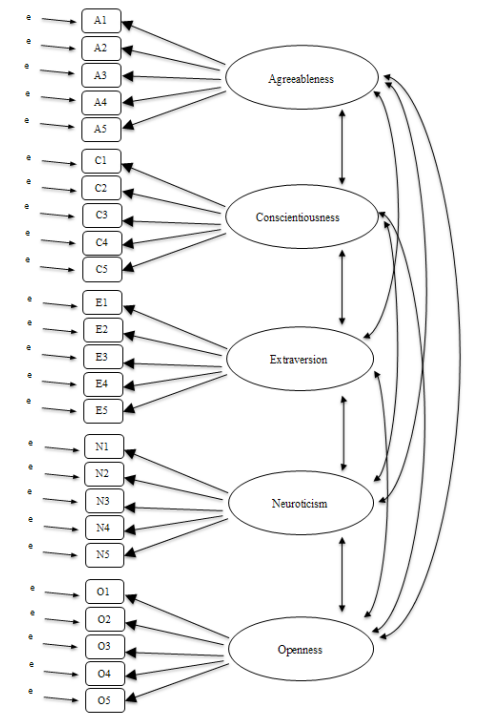
下一步是考慮是否應允許模型中的潛在因素相關。如前所述,在心理學和行為科學中,構念之間通常是相互關聯的,我們也認為我們的一些人格因素可能彼此相關。因此,在我們的模型中,我們應該允許這些潛在因素共變,如 圖 15.13 中的雙箭頭所示。
同時,我們應該考慮是否有任何充分的、系統性的理由讓某些誤差項彼此相關。一個可能的原因是,特定觀察變項子集存在共同的方法學特徵,使得這些觀察變項可能因方法學而非實質潛在因素的原因而相關。我們將在後面的章節中回到這個可能性,但目前,我們看不到任何明確的理由來證明某些誤差項之間應該相關。
在沒有任何相關誤差項的情況下,我們用來檢驗其與觀察資料擬合程度的模型,就如 圖 15.13 所指定。模型中只預期找到包含的參數,因此在CFA中,所有其他可能的參數(係數)都被設定為零。所以,如果這些其他參數不為零(例如,觀察資料中可能存在從A1到潛在因素「外向性」的實質負荷,但在我們的模型中沒有),那麼我們可能會發現我們的模型與觀察資料的擬合度不佳。
好了,讓我們來看看如何在jamovi中設定這個CFA分析。
15.3.1 使用jamovi完成驗證性因素分析
打開 bfi_sample2.csv 檔案,檢查25個變項是否被編碼為次序(或連續)變項;對於此分析,這不會產生任何差異。在jamovi中執行CFA的步驟如下:
- 從jamovi主功能列中選擇「因素分析」(Factor) -> 「驗證性因素分析」(Confirmatory Factor Analysis)以打開CFA分析視窗(圖 15.14)。
- 選取5個A開頭的變項,將它們移至「因素」(Factors)框中,並給予標籤「Agreeableness」。
- 在「因素」框中創建一個新因素,並標記為「Conscientiousness」。選取5個C開頭的變項,將它們移至「Conscientiousness」標籤下的「因素」框中。
- 在「因素」框中再創建一個新因素,並標記為「Extraversion」。選取5個E開頭的變項,將它們移至「Extraversion」標籤下的「因素」框中。
- 在「因素」框中再創建一個新因素,並標記為「Neuroticism」。選取5個N開頭的變項,將它們移至「Neuroticism」標籤下的「因素」框中。
- 在「因素」框中再創建一個新因素,並標記為「Openness」。選取5個O開頭的變項,將它們移至「Openness」標籤下的「因素」框中。
- 檢查其他適當的選項,對於初次操作,預設值即可。不過,您可能想在「繪圖」(Plots)下勾選「路徑圖」(Path diagram)選項,以讓jamovi生成一個與我們的 圖 15.13(相當)相似的圖表。
設定好分析後,我們可以將注意力轉向jamovi的結果視窗,看看結果如何。首先要看的是模型適配度(圖 15.15),因為它告訴我們模型與觀察資料的擬合程度。請注意,在我們的模型中,只估計了預先指定的共變異,預設情況下包括因素相關。其餘所有參數都設定為零。
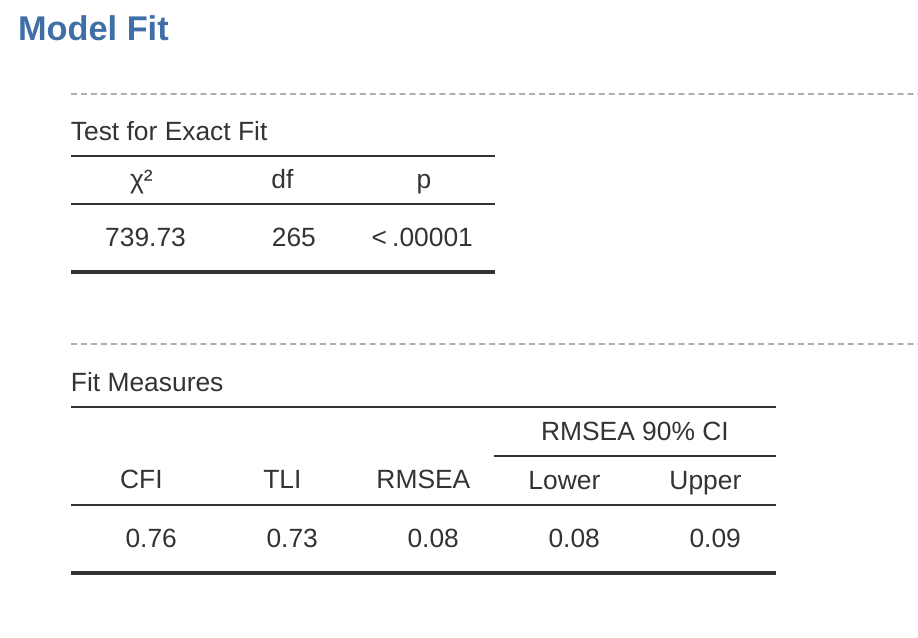
評估模型適配度有幾種方法。第一種是卡方統計量,如果值很小,表示模型與資料擬合良好。然而,用於評估模型適配的卡方統計量對樣本大小相當敏感,這意味著對於大樣本,模型與資料之間足夠好的擬合幾乎總會產生一個大而顯著(\(p < .05\))的卡方值。
因此,我們需要其他方法來評估模型適配度。在jamovi中,預設提供了幾種。這些是比較適配指數(CFI)、塔克-路易斯指數(TLI)和近似誤差均方根(RMSEA)及其90%信賴區間。一些實用的經驗法則是:CFI > 0.9、TLI > 0.9,以及RMSEA約在0.05到0.08之間表示滿意的擬合。CFI > 0.95、TLI > 0.95,以及RMSEA及其信賴區間上限 < 0.05則表示良好的擬合。
從 圖 15.15 中我們可以看到,卡方值很大且高度顯著。我們的樣本量不算太大,所以這可能表示擬合不佳。CFI為0.762,TLI為0.731,表示模型與資料之間的擬合不佳。RMSEA為0.085,90%信賴區間為0.077到0.092,這同樣未顯示出良好的擬合。
相當令人失望,是吧?但考慮到在早前的EFA中,當我們使用類似的資料集(見探索性因素分析一節)時,五因素模型僅解釋了資料中約一半的變異,這個結果或許不太令人意外。
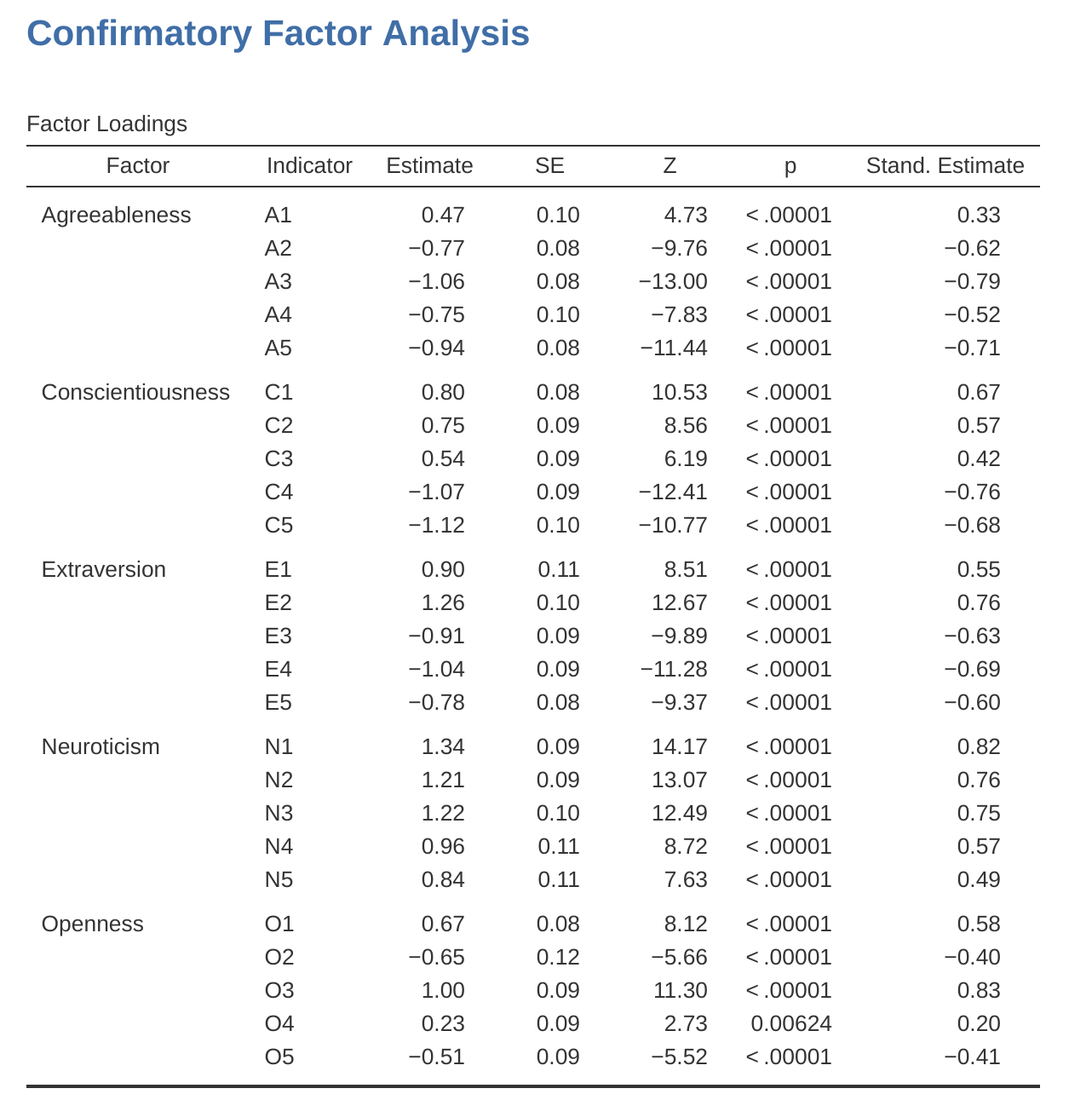
讓我們接著看 圖 15.16 和 圖 15.17 中顯示的因素負荷量和因素共變異估計。每個參數的Z統計量和p值表明它們對模型做出了合理的貢獻(即它們不為零),因此似乎沒有理由從模型中移除任何指定的變項-因素路徑或因素-因素相關。通常標準化估計值更容易解釋,這些可以在「估計」(Estimates)選項下指定。這些表格可以有效地整合到書面報告或科學文章中。
我們該如何改進模型呢?一個選擇是回到前幾個階段,重新思考我們正在使用的項目/測量,以及如何改進或更改它們。另一個選擇是對模型進行一些事後調整以改善擬合度。實現此目的的一種方法是使用「修正指標」(modification indices)(圖 15.18),在jamovi中它被指定為「額外輸出」(Additional output)選項。
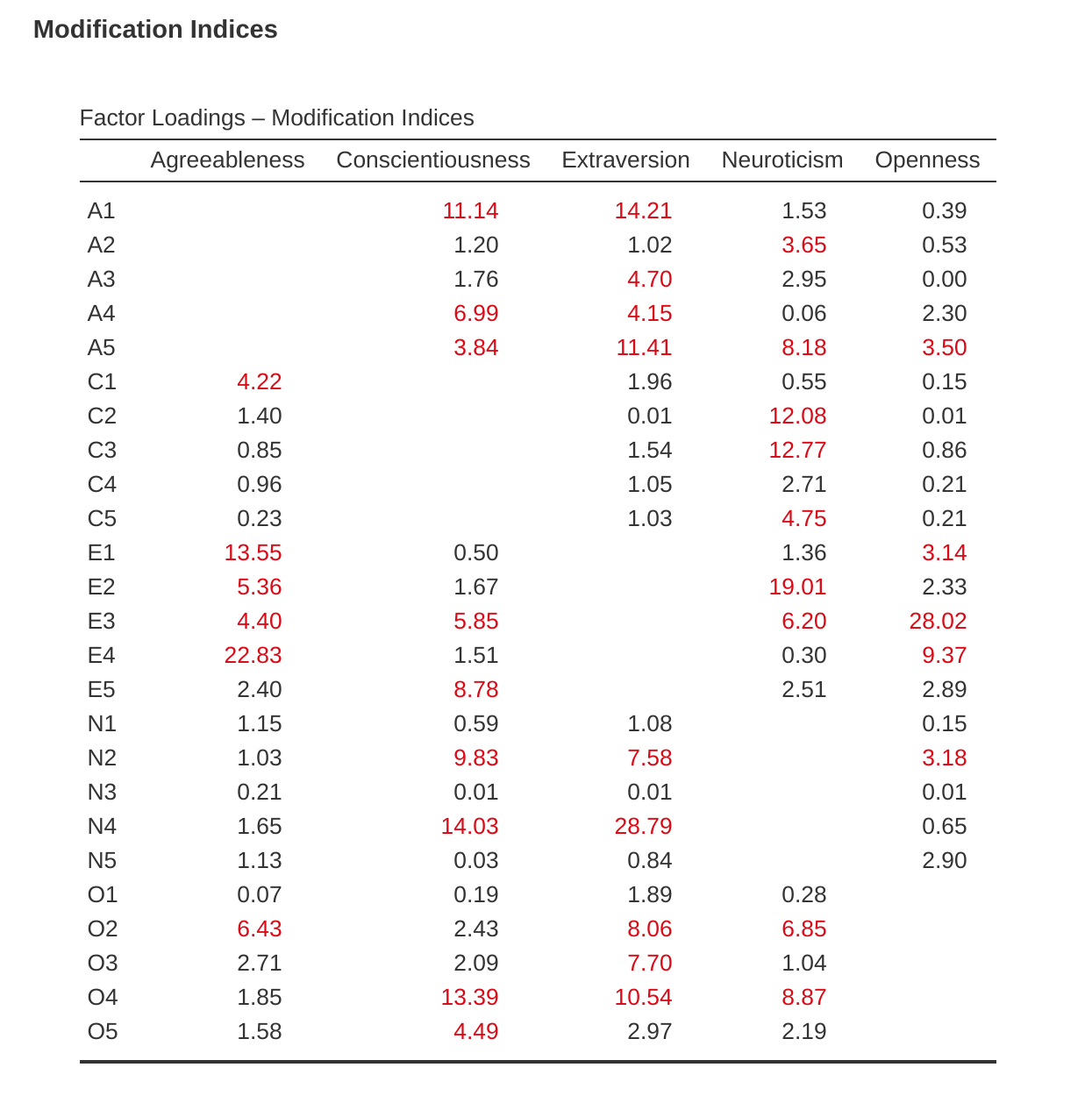
我們要尋找的是最高的修正指標(MI)值。然後,我們將判斷將該附加項加入模型中是否有意義,並使用事後合理化的方式。例如,我們可以在 圖 15.18 中看到,對於模型中尚未包含的因素負荷量,最大的MI值是N4(「經常感到憂鬱」)對潛在因素「外向性」的負荷,其值為28.786。這表示如果我們將此路徑加入模型,卡方值將減少大約相同的量。
但在我們的模型中,加入這條路徑在理論上或方法論上可以說並不合理,所以這不是一個好主意(除非您能提出有說服力的論點,證明「經常感到憂鬱」同時測量神經質性與外向性)。我想不出好的理由。但是,為了論證起見,讓我們假裝它確實有一定意義,並將此路徑加入模型中。回到CFA分析視窗(見 圖 15.14)並將N4加入外向性因素中。CFA的結果現在會改變(未顯示);卡方值下降到約709(下降了約30,大致與MI的大小相當),其他擬合指標也有所改善,儘管只是一點點。但這還不夠:它仍然不是一個擬合良好的模型。
如果您發現自己正在使用MI值向模型中添加新參數,請務必在每次新增後重新檢查MI表,因為MI每次都會重新計算。
jamovi還產生了殘差共變異修正指標表(圖 15.19)。換句話說,這是一個顯示如果將哪些相關誤差加入模型中,可以最大程度地改善模型擬合度的表格。同時查看這兩個MI表是一個好主意,找出最大的MI,思考是否可以合理地證明建議參數的增加,如果可以,就將其加入模型中。然後,您可以在重新計算的結果中再次開始尋找最大的MI。

您可以隨心所欲地以這種方式繼續操作——根據最大的MI將參數加入模型中,最終您將達到令人滿意的擬合效果。但這樣做的同時,也極有可能創造出一個怪物!一個醜陋、畸形、在理論上毫無意義或純粹性的模型。換句話說,要非常小心!
到目前為止,我們已經使用第二個樣本和CFA檢驗了在EFA中獲得的因素結構。不幸的是,我們發現EFA的因素結構在CFA中未得到確認,因此就這個人格量表的開發而言,我們又回到了原點。
儘管我們本可以使用修正指標來調整CFA,但我真的想不出任何好的理由(至少我想不出)來包含這些建議的額外因素負荷量或殘差共變異。然而,在某些情況下,允許殘差共變(或相關)是有充分理由的,下一節關於多特質多方法驗證性因素分析就提供了一個很好的例子。在此之前,讓我們先了解如何報告CFA的結果。
15.3.2 驗證性因素分析的報告須知
CFA報告沒有正式的標準格式,範例因學科和研究人員而異。儘管如此,報告中仍應包含以下幾項標準資訊:
- 假設模型的理論和實證依據。
- 完整描述模型的設定方式(例如,每個潛在因素的指標變項、潛在變項之間的共變異,以及任何誤差項之間的相關)。包含像 圖 15.13 這樣的路徑圖會很有幫助。
- 樣本描述(例如,人口統計資訊、樣本大小、抽樣方法)。
- 所用資料類型的描述(例如,名義、連續)及完整的描述性統計。
- 假設檢定及所用的估計方法。
- 遺失資料的描述及其處理方式。
- 用於擬合模型的軟體及版本。
- 用於判斷模型擬合度的測量指標及標準。
- 基於模型擬合度或修正指標對原始模型所做的任何修改。
- 所有參數估計值(即負荷量、誤差變異、潛在(共)變異)及其標準誤,最好以表格呈現。
15.4 多特質多方法驗證性因素分析
在本節中,我們將探討不同的測量技術或問題如何成為資料變異的一個重要來源,這被稱為方法變異。為此,我們將使用另一個心理學資料集,其中包含關於「歸因風格」的資料。
Hewitt et al. (2004) 使用歸因風格問卷(ASQ)從英國和紐西蘭的年輕人那裡收集心理健康資料。他們測量了負面事件的歸因風格,即人們習慣性地如何解釋發生在他們身上的壞事的原因 (Peterson & Seligman, 1984)。歸因風格問卷(ASQ)測量歸因風格的三個方面:
- 內歸因(Internality)是一個人相信壞事的原因是出於自身行為的程度。
- 穩定性(Stability)是一個人習慣性地相信壞事的原因會隨時間保持穩定的程度。
- 全面性(Globality)是一個人習慣性地相信一個領域的壞事原因會影響到他們生活其他領域的程度。
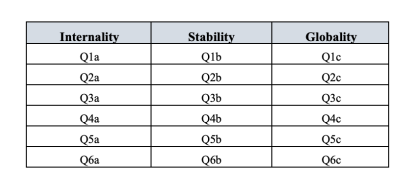
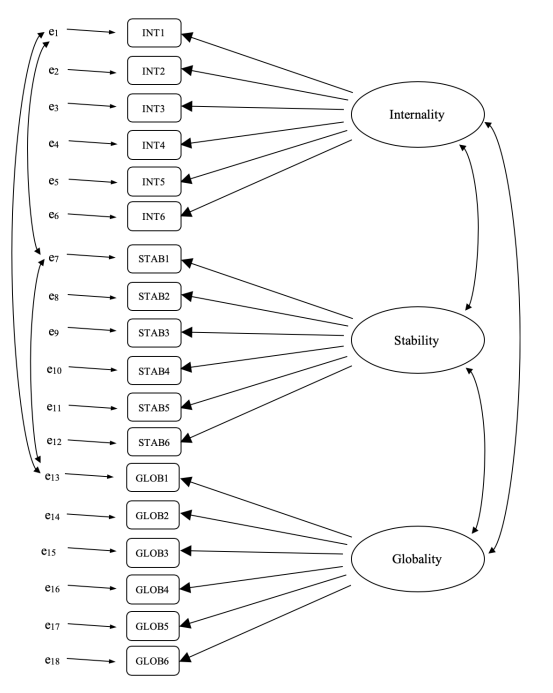
問卷中有六個假設情境,對於每個情境,受訪者需回答旨在測量(a)內歸因、(b)穩定性和(c)全面性的問題。因此,總共有 \(6 \times 3 = 18\) 個項目。更多細節請參見 圖 15.20。

研究人員有興趣檢驗他們的資料,看看ASQ中的18個觀察變項是否能合理地測量某些潛在因素。
首先,他們對這18個變項進行EFA(未顯示),但無論如何萃取或轉軸,都找不到一個好的因素解。他們試圖在歸因風格問卷(ASQ)中識別潛在因素的嘗試證明是徒勞的。如果得到這樣的結果,那麼要麼您的理論是錯誤的(歸因風格可能沒有潛在因素結構,這是可能的),要麼樣本不具代表性(考慮到這個來自英國和紐西蘭的年輕成人樣本的大小和特徵,這不太可能),要麼分析方法不適合這項工作。我們將探討第三種可能性。
回想一下,ASQ測量了三個構面:內歸因、穩定性和全面性,每個構面由六個問題測量,如 圖 15.21 所示。
如果我們不以探索性的方式分析資料如何組合,而是將一個結構(如 圖 15.21 所示)強加於資料之上,然後看資料與我們預先指定的結構的擬合程度,會怎麼樣呢?從這個意義上說,我們是在進行驗證性分析,以檢視一個預先指定的模型在多大程度上被觀察資料所證實。
因此,對ASQ進行直接的驗證性因素分析(CFA)將指定三個潛在因素,如 圖 15.21 的欄位所示,每個因素由六個觀察變項測量。
我們可以將此描繪成 圖 15.22 中的圖表,該圖顯示每個變項都是一個潛在因素的測量指標。例如,INT1由潛在因素「內歸因」預測。而且因為INT1不是內歸因因素的完美測量,所以有一個與之相關的誤差項 \(e_1\)。換句話說,\(e_1\) 代表了INT1中無法被內歸因因素解釋的變異,這有時被稱為「測量誤差」。
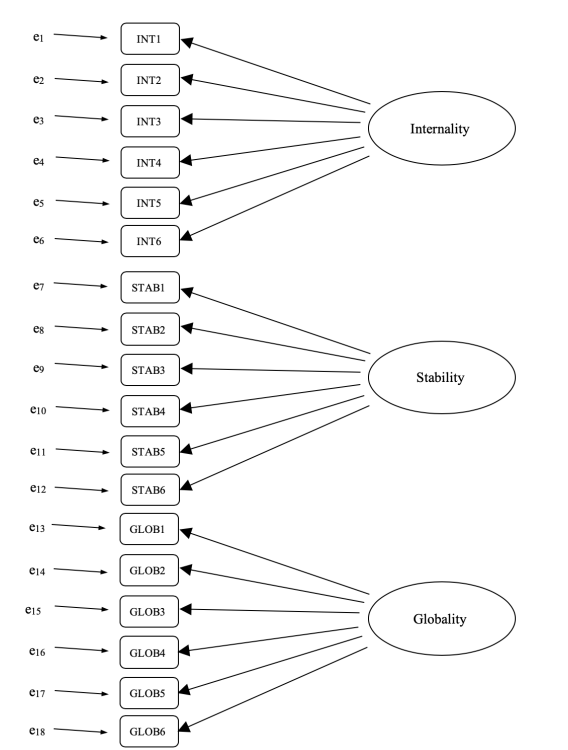
下一步是考慮是否應允許模型中的潛在因素相關。如前所述,在心理學和行為科學中,構念之間通常是相互關聯的,我們也認為內歸因、穩定性和全面性可能彼此相關,因此在我們的模型中,我們應該允許這些潛在因素共變,如 圖 15.23 所示。
同時,我們應該考慮是否有任何充分的、系統性的理由讓某些誤差項彼此相關。回想ASQ的問題,每個主要問題(1-6)都有三個不同的子問題(a、b和c)。Q1是關於求職失敗,這個問題可能比其他問題(2-5)具有某些獨特的人為或方法論方面,也許與求職有關。同樣地,Q2是關於不幫助朋友解決問題,在不幫助朋友這一點上,可能存在某些獨特的人為或方法論方面,而這是其他問題(1和3-5)所沒有的。
因此,除了多個因素外,ASQ中還存在多種方法學特徵,其中每個問題1-6都有略微不同的「方法」,但每個「方法」在子問題a、b和c之間是共享的。為了將這些不同的方法學特徵納入模型,我們可以指定某些誤差項彼此相關。例如,與INT1、STAB1和GLOB1相關的誤差應該彼此相關,以反映Q1a、Q1b和Q1c的獨特和共享的方法學變異。從 圖 15.21 來看,這意味著除了由欄位代表的潛在因素外,我們還將對表中每一列的變項有相關的測量誤差。
雖然像 圖 15.22 所示的基本CFA模型可以與我們的觀察資料進行檢驗,但我們實際上提出了一個更複雜的模型,如 圖 15.23 的圖表所示。這種更複雜的CFA模型被稱為多特質多方法(MTMM)模型,這就是我們將在jamovi中檢驗的模型。
15.4.1 使用jamovi完成多特質多方法驗證性因素分析
打開 ASQ.csv 檔案,並檢查18個變項(六個「內歸因」、六個「穩定性」和六個「全面性」變項)是否被指定為連續變項。
在jamovi中執行MTMM CFA的步驟如下:
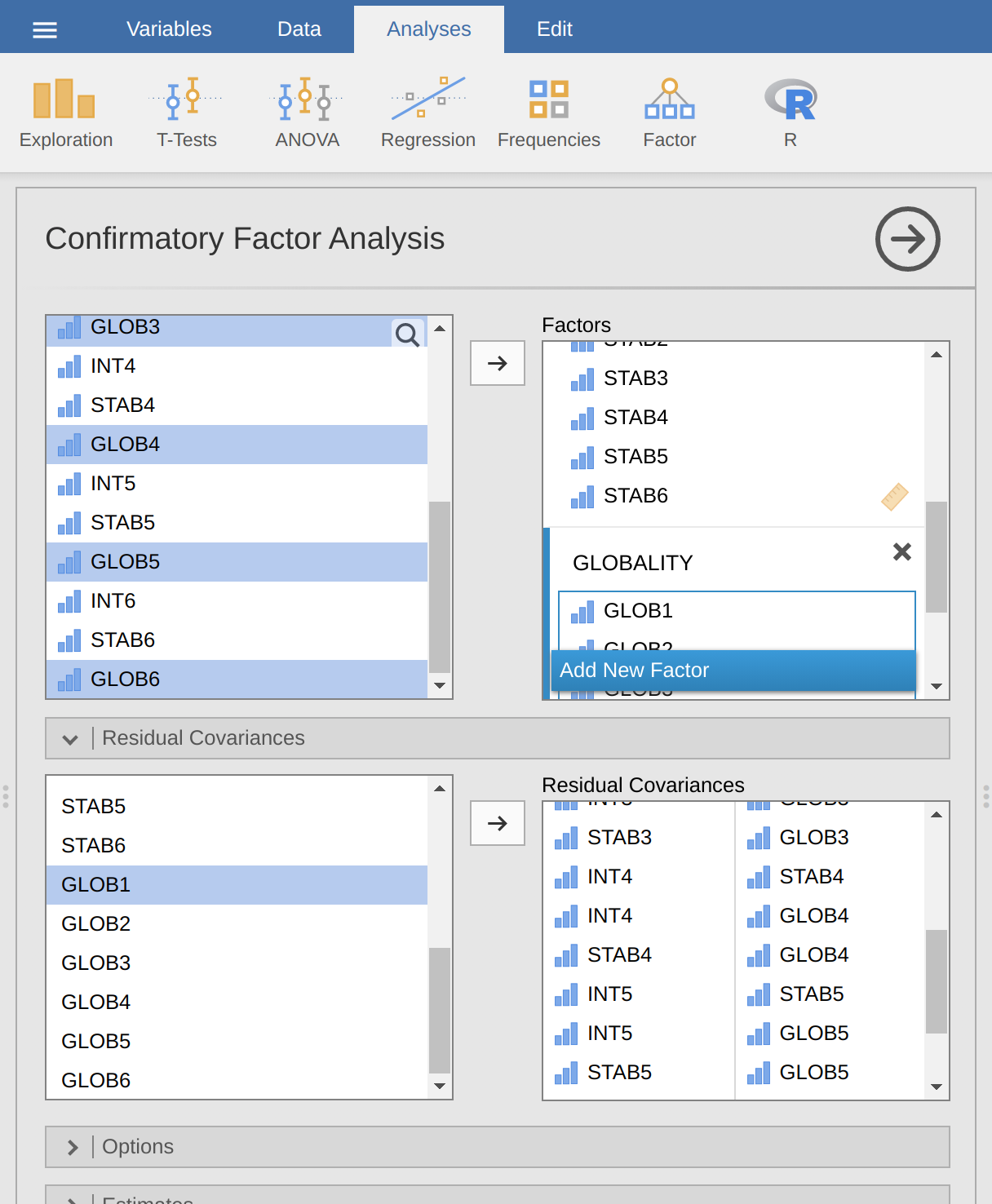
- 從jamovi主功能列中選擇「因素分析」(Factor) -> 「驗證性因素分析」(Confirmatory Factor Analysis)以打開CFA分析視窗(圖 15.24)。
- 選取6個INT變項,將它們移至「因素」(Factors)框中,並給予標籤「Internality」。
- 在「因素」框中創建一個新因素,並標記為「Stability」。選取6個STAB變項,將它們移至「Stability」標籤下的「因素」框中。
- 在「因素」框中再創建一個新因素,並標記為「Globality」。選取6個GLOB變項,將它們移至「Globality」標籤下的「因素」框中。
- 打開「殘差共變異」(Residual Covariances)選項,對於每個預先指定的相關,將相關的變項移至右側的「殘差共變異」框中。例如,同時反白INT1和STAB1,然後點擊箭頭將它們移過去。現在對INT1和GLOB1、STAB1和GLOB1、INT2和STAB2、INT2和GLOB2、STAB2和GLOB2、INT3和STAB3等執行相同操作。
- 檢查其他適當的選項,對於初次操作,預設值即可。不過,您可能想在「繪圖」(Plots)下勾選「路徑圖」(Path diagram)選項,以讓jamovi生成一個與我們的 圖 15.23(相當)相似的圖表,並包含我們上面添加的所有誤差項相關。
一旦設定好分析,我們就可以將注意力轉向jamovi的結果視窗,看看結果如何。首先要看的是「模型適配度」,因為它告訴我們模型與觀察資料的擬合程度(圖 15.25)。請注意,在我們的模型中,只估計了預先指定的共變異,其餘所有參數都設定為零,所以模型適配度測試的是預先指定的「自由」參數是否不為零,反之,資料中我們未在模型中指定的其他關係是否可以保持為零。
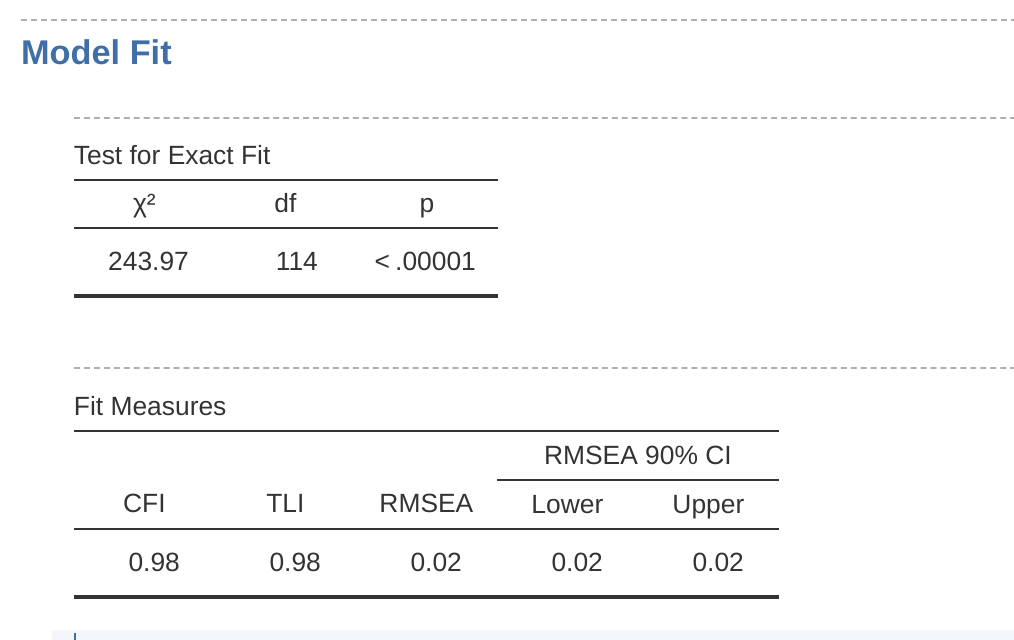
從 圖 15.25 中我們可以看到,卡方值非常顯著,考慮到樣本量很大(N = 2748),這一點也不足為奇。CFI為0.98,TLI也為0.98,表示模型擬合非常好。RMSEA為0.02,90%信賴區間為0.02到0.02——非常精確!
總的來說,我認為我們可以滿意地認為我們預先指定的模型與觀察資料的擬合非常好,這為我們的ASQ之MTMM模型提供了支持。
現在我們可以繼續查看因素負荷量和因素共變異估計,如 圖 15.26 所示。通常標準化估計值更容易解釋,這些可以在「估計」(Estimates)選項下指定。這些表格可以有效地整合到書面報告或科學文章中。
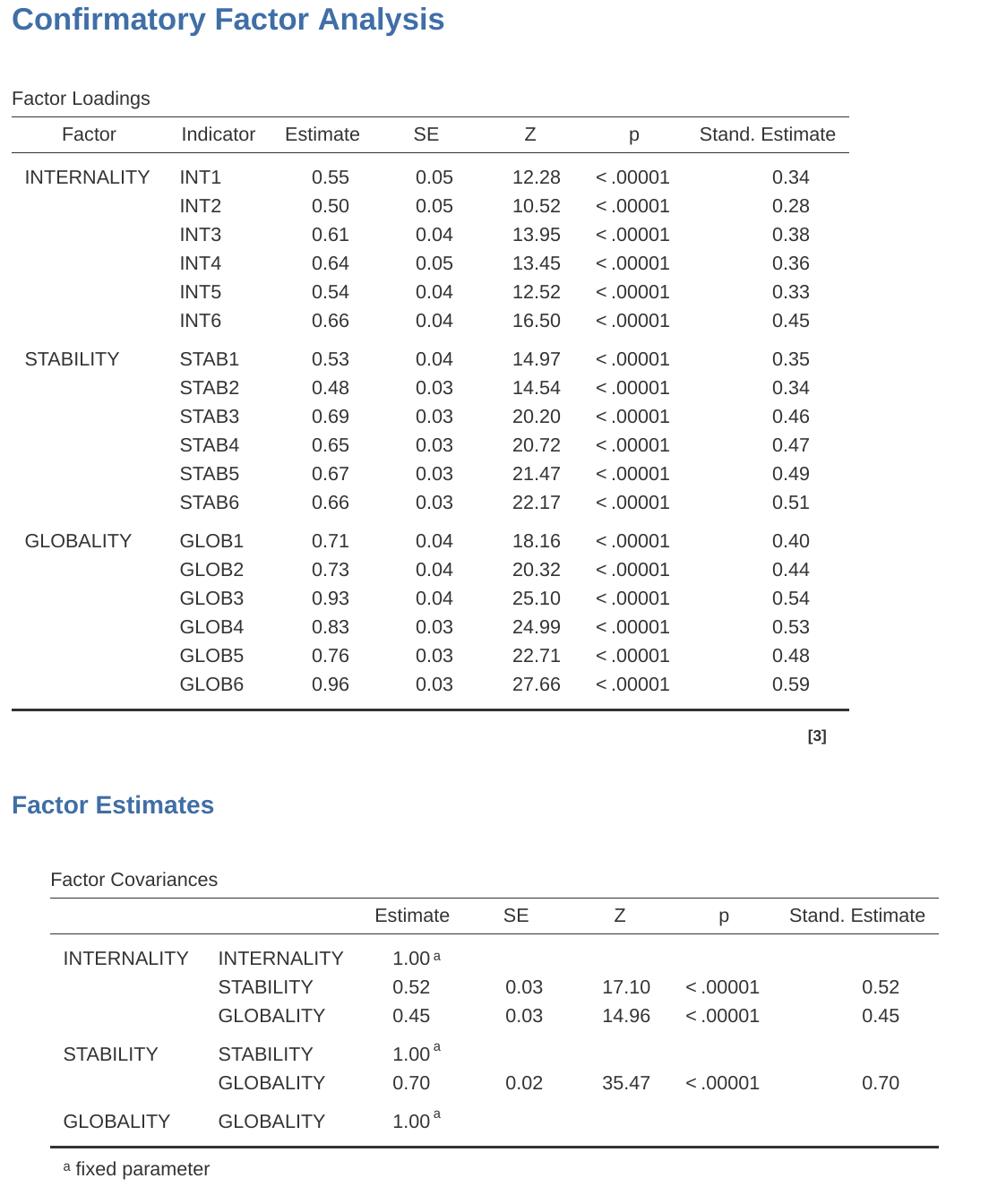
從 圖 15.26 您可以看到,我們預先指定的所有因素負荷量和因素共變異都顯著不為零。換句話說,它們似乎都在為模型做出有用的貢獻。
在這次分析中,我們相當幸運,在第一次嘗試就得到了非常好的擬合效果!
15.5 內部一致性信度分析
在您經歷了使用EFA和CFA進行初始量表開發的過程後,您應該已經達到一個階段,即量表在使用不同樣本的CFA中表現得相當不錯。在這個階段,您可能還會有興趣看看使用結合觀察變項的量表來測量因素的效果如何。
在心理計量學中,我們使用信度分析來提供關於一個量表測量某個心理構念的穩定性資訊(請參閱前面關於 小單元 2.3 的章節)。我們這裡關心的是內部一致性,它指的是構成一個測量量表的所有個別項目之間的一致性。因此,如果我們有 \(V1, V2, V3, V4\) 和 \(V5\) 作為觀察項目變項,我們就可以計算一個統計量,告訴我們這些項目在測量潛在構念方面的內部一致性如何。
一個常用於檢查量表內部一致性的統計量是克隆巴赫α係數 (Cronbach’s alpha) (Chronbach, 1951)。克隆巴赫α係數是等價性的一種測量(即不同組的量表項目是否會給出相同的測量結果)。等價性是透過將量表項目分成兩組(「折半」)並觀察兩部分的分析是否給出可比較的結果來檢驗的。當然,一組項目可以有多種折半方式,但如果進行所有可能的折半,就有可能產生一個反映折半係數整體模式的統計量。克隆巴赫α係數(\(\alpha\))就是這樣一個統計量:一個量表所有折半係數的函數。如果一組測量某個構念(例如外向性量表)的項目其 \(\alpha\) 為0.80,那麼該量表的誤差變異比例為0.20。換句話說,\(\alpha\) 為0.80的量表包含大約20%的誤差。
但是(這是一個很大的「但是」),克隆巴赫α係數並非單維性的測量(即一個指標,表明一個量表是測量單一因素或構念,而不是多個相關的構念)。如果多維度的量表沒有對每個維度分開評估,會導致α係數被低估,但高的α值不必然是單維性的指標。因此,\(\alpha\) 為0.80並不意味著80%來自單一潛在構念。這80%可能來自多於一個潛在構念。這就是為什麼先做EFA和CFA很有用。
此外,\(\alpha\) 的另一個特點是它傾向於樣本特定:它不是量表的特性,而是使用該量表的樣本的特性。一個有偏誤、不具代表性或小樣本可能產生與大而具代表性的樣本截然不同的 \(\alpha\) 係數。\(\alpha\) 甚至可以在不同的大樣本之間變化。儘管有這些限制,克隆巴赫α係數在心理學中一直被廣泛用於估計內部一致性信度。它計算簡單、易於理解和解釋,因此當您在不同樣本、不同情境或族群中使用量表時,它可以作為一個有用的初步檢查量表表現的指標。
另一種選擇是麥當勞ω係數 (McDonald’s omega)(\(\omega\)),jamovi也提供此統計量。\(\alpha\) 係數有以下假設:(a)無殘差相關,(b)項目具有相同的負荷量,以及(c)量表是單維的,而 \(\omega\) 則沒有這些假設,因此是一個更穩健的信度統計量。如果這些假設未被違反,\(\alpha\) 和 \(\omega\) 會相似,但如果被違反,則應優先選擇 \(\omega\)。
有時會提供 \(\alpha\) 或 \(\omega\) 的閾值,建議一個「足夠好」的值。例如 \(\alpha\) 為0.70或0.80分別代表「可接受」和「良好」的信度。然而,這確實取決於量表確切要測量的是什麼,所以應謹慎使用這樣的閾值。更好的做法可能是簡單地陳述 \(\alpha\) 或 \(\omega\) 為0.70與量表中30%的誤差變異相關,而 \(\alpha\) 或 \(\omega\) 為0.80與20%的誤差變異相關。
\(\alpha\) 會不會太高?可能會:如果您得到的 \(\alpha\) 係數高於0.95,這表示項目之間有很高的相互關聯,測量中可能存在過多的冗餘特異性,有風險的是所測量的構念可能過於狹隘。
15.5.1 使用jamovi完成內部一致性信度分析
我們有第三份人格資料樣本可用於進行信度分析:在 bfi_sample3.csv 檔案中。再次檢查25個人格項目變項是否被編碼為連續變項。在jamovi中執行信度分析的步驟如下:
- 從jamovi主功能列中選擇「因素分析」(Factor) -> 「信度分析」(Reliability Analysis)以打開信度分析視窗(圖 15.27)。
- 選取5個A開頭的變項,將它們移至「項目」(Items)框中。
- 在「反向計分項目」(Reverse Scaled Items)選項下,在「正常計分項目」(Normal Scaled Items)框中選取變項A1,並將其移至「反向計分項目」框中。
- 檢查其他適當的選項,如 圖 15.27 所示。
完成後,查看jamovi的結果視窗。您應該會看到類似 圖 15.28 的內容。這告訴我們親和性量表的克隆巴赫α係數為0.72。這意味著親和性量表分數中略低於30%是誤差變異。同時也給出了麥當勞ω係數,為0.74,與α沒有太大區別。
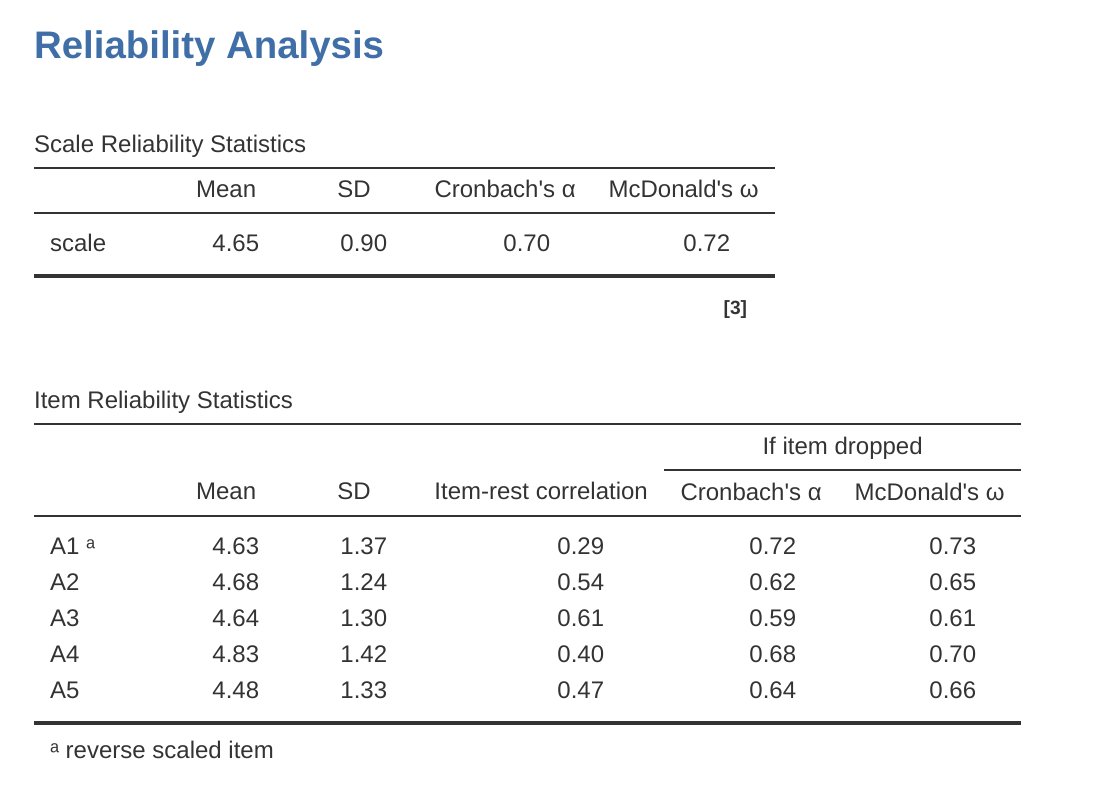
我們也可以檢查如果從量表中刪除特定項目,α或ω如何得到改善。例如,如果刪除項目A1,α將增加到0.74,ω增加到0.75。這個增幅並不大,所以可能不值得這樣做。
計算和檢查量表統計量(α和ω)的過程對於所有其他量表也是相同的,除了開放性之外,它們都有類似的信度估計。對於開放性,量表分數中的誤差變異量約為40%,這很高,並表明與其他人格量表相比,開放性作為人格屬性的可靠測量的一致性要差得多。
15.6 本章小結
在關於因素分析及相關技術的本章中,我們介紹並示範了評估資料集中關係模式的統計分析。具體來說,我們涵蓋了:
- 探索性因素分析:EFA是一種用於識別資料集中潛在因素的統計技術。每個觀察變項在概念上被視為在某種程度上代表潛在因素,由因素負荷量表示。研究人員也使用EFA作為資料降維的一種方式,即識別可以組合成新因素變項以供後續分析的觀察變項。
- 主成分分析:PCA是一種資料降維技術,嚴格來說,它並非用來識別潛在因素,而是產生觀察變項的線性組合。
- 驗證性因素分析:與EFA不同,進行CFA時,您從一個關於資料中變項如何相互關聯的想法——一個模型——開始。然後,您根據觀察資料檢驗您的模型,並評估模型與資料的擬合程度。
- 在多特質多方法驗證性因素分析中,潛在因素和方法變異都包含在模型中,這種方法在使用了不同的方法論途徑,因此方法變異是一個重要考量時非常有用。
- 內部一致性信度分析:這種信度分析形式檢驗一個量表測量某個(心理)構念的穩定程度。
因素負荷量的解讀方式類似於標準化迴歸係數。↩︎
斜交轉軸會提供兩個因素矩陣,一個稱為結構矩陣(structure matrix),另一個稱為模式矩陣(pattern matrix)。在jamovi中,結果只會顯示模式矩陣,因為這通常對解釋最有用,不過有些專家建議兩者皆有助益。在結構矩陣中,係數顯示變項與因素之間的關係,同時忽略該因素與所有其他因素的關係(即零階相關)。模式矩陣的係數則顯示一個因素對一個變項的獨特貢獻,同時控制了其他因素對該變項的影響(類似於標準化偏迴歸係數)。在正交轉軸下,結構係數和模式係數是相同的。↩︎
因素分析中有時會報告「共同性」(communality),這是指一個變項中能被因素解解釋的變異量。獨特性等於(1 - 共同性)。↩︎
如有必要,記得先對某些變項進行反向計分。↩︎
順帶一提,鑑於我們從最初的「假定」因素中已經有了相當明確的想法,我們本可以直接進行CFA而跳過EFA步驟。是先用EFA再進行CFA,還是直接進行CFA,取決於判斷以及您最初對模型(在因素和變項數量方面)的正確性有多大信心。在量表開發的早期階段,或在識別潛在構念時,研究人員傾向於使用EFA。後期,當他們接近最終量表,或者想在新樣本中檢驗一個已建立的量表時,CFA是一個很好的選擇。↩︎